
组件
| 组件 | 版本 | 端口号 | 链接 |
|---|---|---|---|
| kibana | v7.17.3 | 默认端口:5601 | https://www.elastic.co/cn/downloads/kibana |
| elasticsearch | v7.17.3 | HTTP RESTful API 默认端口:9200 HTTPS RESTful API 默认端口:9201 节点之间进行通信的默认端口:9300 Head 插件默认端口号:9100 | https://www.elastic.co/cn/downloads/elasticsearch |
| logstash | v7.17.3 | HTTP 输入插件端口:5044 Beats 输入插件端口:5044 Syslog 输入插件端口:514 Logstash 监控 API 端口:9600 TCP通信端口默认为:8888 | https://www.elastic.co/cn/downloads/logstash |
| scala+kafka | v2.13-v3.6.2 | Broker 监听端口:9092 JMX 端口:9999 Kafka REST 代理端口:8082 Schema Registry 端口:8081 Kafka Connect REST API 端口:8083 | https://kafka.apache.org |
| zookeeper | v3.8.4 | 默认端口:2181 Leader 选举端口:2888 集群通信端口:3888 | https://zookeeper.apache.org/releases.html |
| filebeat | v7.17.3 | 本身无固定端口,使用ELK框架中的其他组件端口,如: 通过Logstash端口进行输出,默认为:5044(5000) | https://www.elastic.co/cn/downloads/beats/filebeat |
| jdk | v1.8.0 | https://www.oracle.com/java/technologies/downloads/archive/ |
部署要求
部分部署要求可参考下方,更多内容请点击官方链接:支持一览表 | Elastic
产品和JVM
Elasticsearch 和 JVM
上次更新时间:2024-06-05
| Oracle/OpenJDK**/AdoptOpenJDK 1.8.0 | Oracle/OpenJDK** 9 | Oracle/OpenJDK** 10 | Oracle/OpenJDK** 11 | AdoptOpenJDK 11 | Oracle/OpenJDK** 12 | Oracle/OpenJDK**/AdoptOpenJDK 13 | Oracle/OpenJDK**/AdoptOpenJDK 14 | Oracle/OpenJDK**/AdoptOpenJDK 15 | Oracle/OpenJDK**/AdoptOpenJDK/Temurin 16 | Oracle/OpenJDK**/Temurin 17 | Oracle/OpenJDK**/Temurin 18 | Oracle/OpenJDK**/Temurin 19 | Oracle/OpenJDK**/Temurin 20 | Oracle/OpenJDK**/Temurin 21 | Oracle/OpenJDK**/Temurin 22 | Azul Zing 16.01.9.0+ | IBM J9 (any version) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Elasticsearch 5.0.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 5.1.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 5.2.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 5.3.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 5.4.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 5.5.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 5.6.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ✔ | X |
| Elasticsearch 6.0.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.1.x | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.2.x | ✔ | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.3.x | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.4.x | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.5.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.6.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.7.x | ✔ | X | X | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 6.8.x | ✔ | X | X | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | X | X | X | X | X | X |
| Elasticsearch 7.0.x | ✔ | X | X | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.1.x | ✔ | X | X | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.2.x | ✔ | X | X | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.3.x | ✔ | X | X | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.4.x | ✔ | X | X | ✔ | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.5.x | ✔ | X | X | ✔ | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.6.x | ✔ | X | X | ✔ | ✔ | X | ✔ | X | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.7.x | ✔ | X | X | ✔ | ✔ | X | X | ✔ | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.8.x | ✔ | X | X | ✔ | ✔ | X | X | ✔ | X | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.9.x | ✔ | X | X | ✔ | ✔ | X | X | ✔ | ✔ | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.10.x | ✔ | X | X | ✔ | ✔ | X | X | ✔ | ✔ | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.11.x | ✔ | X | X | ✔ | ✔ | X | X | X | ✔ | X | X | X | X | X | X | X | X | X |
| Elasticsearch 7.12.x | ✔ | X | X | ✔ | ✔ | X | X | X | ✔ | ✔ | X | X | X | X | X | X | X | X |
| Elasticsearch 7.13.x | ✔ | X | X | ✔ | ✔ | X | X | X | X | ✔ | X | X | X | X | X | X | X | X |
| Elasticsearch 7.14.x | ✔ | X | X | ✔ | ✔ | X | X | X | X | ✔ | X | X | X | X | X | X | X | X |
| Elasticsearch 7.15.x | ✔ | X | X | ✔ | ✔ | X | X | X | X | ✔ | ✔ | X | X | X | X | X | X | X |
| Elasticsearch 7.16.x | ✔ | X | X | ✔ | ✔ | X | X | X | X | X | ✔ | X | X | X | X | X | X | X |
| Elasticsearch 7.17.x | ✔ | X | X | ✔ | ✔ | X | X | X | X | X | ✔ | ✔ | ✔ | ✔ | [1] | [2] | X | X |
| Elasticsearch 8.0.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | X | X | X | X | X |
| Elasticsearch 8.1.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | X | X | X | X | X | X |
| Elasticsearch 8.2.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | X | X | X | X | X | X |
| Elasticsearch 8.3.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | X | X | X | X | X | X |
| Elasticsearch 8.4.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | X | X | X | X | X | X |
| Elasticsearch 8.5.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | ✔ | X | X | X | X | X |
| Elasticsearch 8.6.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | ✔ | X | X | X | X | X |
| Elasticsearch 8.7.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | ✔ | ✔ | X | X | X | X |
| Elasticsearch 8.8.x | X | X | X | X | X | X | X | X | X | X | ✔ | ✔ | ✔ | ✔ | X | X | X | X |
| Elasticsearch 8.9.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | ✔ | X | X | X | X |
| Elasticsearch 8.10.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | ✔ | ✔ | X | X | X |
| Elasticsearch 8.11.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | X | ✔ | X | X | X |
| Elasticsearch 8.12.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | X | ✔ | X | X | X |
| Elasticsearch 8.13.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | X | ✔ | ✔ | X | X |
| Elasticsearch 8.14.x | X | X | X | X | X | X | X | X | X | X | ✔ | X | X | X | ✔ | ✔ | X | X |
Java 9、Java 10、Java 12、Java 13、Java 14、Java 15 和 Java 16 均为短期版本。我们建议不要使用以上版本,除非您准备好应对这种快速发布节奏。有关 JVM 支持,请参见 Oracle 的时间表,网址为:http://www.oracle.com/technetwork/java/eol-135779.html
**Elastic 支持部分 OpenJDK 派生的分发版:1. 由 IcedTea 项目构建;2. 操作系统供应商在“产品和操作系统”矩阵中生产并通过 TCK 测试的产品;3. Azul Zulu 从 Elasticsearch 6.6.0 版开始。
此页面上的 Elasticsearch/JVM 支持信息适用于服务器和客户端(例如,客户端 API)的实现。
FIPS 140-2 模式需要 Oracle JDK 11 (Elasticsearch 7.x) 或 Oracle JDK 17 (Elasticsearch 8.13+) 和 Bouncy Castle BCJSSE FIPS 安全提供程序
*** Elasticsearch 8.8.x+ 包括 Elasticsearch 模块(行为分析和搜索应用程序)中提供的企业搜索功能的相关兼容性信息
[1] 从 7.17.14 起支持 JDK21
[2] 从 7.17.19 起支持 JDK22
Logstash 和 JVM
上次更新时间:2024-06-05
| Oracle/OpenJDK 1.8.0 | Oracle/OpenJDK 9 | Oracle/OpenJDK 10 | Oracle/OpenJDK* 11 | AdoptOpenJDK 11 | Oracle/OpenJDK*/AdoptOpenJDK 14 | Oracle/OpenJDK*/AdoptOpenJDK 15 | Oracle/OpenJDK*/Temurin 17 | Oracle/OpenJDK*/Temurin 18 | Azul Zing 16.01.9.0+ | IBM J9 (any version) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Logstash 5.0.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 5.1.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 5.2.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 5.3.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 5.4.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 5.5.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 5.6.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.0.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.1.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.2.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.3.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.4.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.5.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.6.x | ✔ | X | X | X | X | X | X | X | X | X | X |
| Logstash 6.7.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 6.8.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.0.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.1.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.2.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.3.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.4.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.5.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.6.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.7.x | ✔ | X | X | ✔ | X | X | X | X | X | X | X |
| Logstash 7.8.x | ✔ | X | X | ✔ | ✔ | ✔ | X | X | X | X | X |
| Logstash 7.9.x | ✔ | X | X | ✔ | ✔ | ✔ | X | X | X | X | X |
| Logstash 7.10.x | ✔ | X | X | ✔ | ✔ | ✔ | X | X | X | X | X |
| Logstash 7.11.x | ✔ | X | X | ✔ | ✔ | ✔ | X | X | X | X | X |
| Logstash 7.12.x | ✔ | X | X | ✔ | ✔ | ✔ | ✔ | X | X | X | X |
| Logstash 7.13.x | ✔ | X | X | ✔ | ✔ | ✔ | ✔ | X | X | X | X |
| Logstash 7.14.x | ✔ | X | X | ✔ | ✔ | ✔ | ✔ | X | X | X | X |
| Logstash 7.15.x | ✔ | X | X | ✔ | ✔ | X | ✔ | X | X | X | X |
| Logstash 7.16.x | ✔ | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 7.17.x | ✔ | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.0.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.1.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.2.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.3.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.4.x | X | X | X | ✔ | ✔ | X | X | ✔ | ✔ | X | X |
| Logstash 8.5.x | X | X | X | ✔ | ✔ | X | X | ✔ | ✔ | X | X |
| Logstash 8.6.x | X | X | X | ✔ | ✔ | X | X | ✔ | ✔ | X | X |
| Logstash 8.7.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.8.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.9.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.10.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.11.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.12.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.13.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
| Logstash 8.14.x | X | X | X | ✔ | ✔ | X | X | ✔ | X | X | X |
* 从 Logstash 7.8.0 版开始支持 Azul Zulu。
产品兼容性
下表显示了有资格获得我们订阅产品支持的平台 和软件配置。请进一步了解我们的 支持政策和产品生命周期结束政策。
没有看到您喜爱的平台、JVM 或浏览器? 请联系我们。
下载我们的软件需要 TLSv1.2 或更高版本。一些较旧的操作系统(或 libcurl、curl 和 apt-get 或 yum 使用的 nss 库)可能需要升级到能够支持 TLSv1.2 的版本, 以便使用软件包安装下载文件。有关详细信息,请参阅您的 操作系统文档。
与 Elasticsearch(5.x、6.x、7.x、8.x)的兼容性
上次更新时间:2024-06-05
| Elasticsearch | Kibana | X-Pack | Beats^* | Elastic Agent^* | Logstash^* | ES-Hadoop (jar) | APM Server | App Search | Enterprise Search | Connector Clients* |
| 5.0.x | 5.0.x | 5.0.x | 1.3.x-5.6.x | 2.4.x-5.6.x | 5.0.x-5.6.x | |||||
| 5.1.x | 5.1.x | 5.1.x | 1.3.x-5.6.x | 2.4.x-5.6.x | 5.0.x-5.6.x | |||||
| 5.2.x | 5.2.x | 5.2.x | 1.3.x-5.6.x | 2.4.x-5.6.x | 5.0.x-5.6.x | |||||
| 5.3.x | 5.3.x | 5.3.x | 1.3.x-5.6.x | 2.4.x-5.6.x | 5.0.x-5.6.x | |||||
| 5.4.x | 5.4.x | 5.4.x | 1.3.x-5.6.x | 2.4.x-5.6.x | 5.0.x-5.6.x | |||||
| 5.5.x | 5.5.x | 5.5.x | 1.3.x-5.6.x | 2.4.x-5.6.x | 5.0.x-5.6.x | |||||
| 5.6.x | 5.6.x | 5.6.x | 1.3.x-6.0.x | 2.4.x-6.0.x | 5.0.x-6.0.x | |||||
| 6.0.x | 6.0.x | 6.0.x | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | |||||
| 6.1.x | 6.1.x | 6.1.x | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | |||||
| 6.2.x | 6.2.x | 6.2.x | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 6.3.x | 6.3.x | N/A** | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 6.4.x | 6.4.x | N/A** | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 6.5.x | 6.5.x | N/A** | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 6.6.x | 6.6.x | N/A** | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 6.7.x | 6.7.x | N/A** | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 6.8.x | 6.8.x | N/A** | 5.6.x-6.8.x | 5.6.x-6.8.x | 6.0.x-6.8.x | 6.2.x-6.8.x | ||||
| 7.0.x | 7.0.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | ||||
| 7.1.x | 7.1.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | ||||
| 7.2.x | 7.2.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | 7.2.x | |||
| 7.3.x | 7.3.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | 7.3.x | |||
| 7.4.x | 7.4.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | 7.4.x | |||
| 7.5.x | 7.5.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | 7.5.x | |||
| 7.6.x | 7.6.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | 7.6.x | |||
| 7.7.x | 7.7.x | N/A** | 6.8.x-7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.7.x | ||
| 7.8.x | 7.8.x | N/A** | 6.8.x-7.17.x | 7.8.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.8.x | |
| 7.9.x | 7.9.x | N/A** | 6.8.x-7.17.x | 7.9.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.9.x | |
| 7.10.x | 7.10.x | N/A** | 6.8.x-7.17.x | 7.10.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.10.x | |
| 7.11.x | 7.11.x | N/A** | 6.8.x-7.17.x | 7.11.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.11.x | |
| 7.12.x | 7.12.x | N/A** | 6.8.x-7.17.x | 7.12.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.12.x | |
| 7.13.x | 7.13.x | N/A** | 6.8.x-7.17.x | 7.13.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.13.x | |
| 7.14.x | 7.14.x | N/A** | 6.8.x-7.17.x | 7.14.x***** | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.14.x | |
| 7.15.x | 7.15.x | N/A** | 6.8.x-7.17.x | 7.14.x - 7.15.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.15.x | |
| 7.16.x | 7.16.x | N/A** | 6.8.x-7.17.x | 7.14.x - 7.16.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.16.x | |
| 7.17.x | 7.17.x | N/A** | 6.8.x-7.17.x | 7.14.x - 7.17.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** | N/A**** | 7.17.x | |
| 8.0.x | 8.0.x | N/A** | 7.17.x - 8.0.x | 7.17.x - 8.0.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x-8.0.x | |
| 8.1.x | 8.1.x | N/A** | 7.17.x - 8.1.x | 7.17.x - 8.1.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x-8.1.x | |
| 8.2.x | 8.2.x | N/A** | 7.17.x - 8.2.x | 7.17.x - 8.2.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x-8.2.x | |
| 8.3.x | 8.3.x | N/A** | 7.17.x - 8.3.x | 7.17.x - 8.3.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x-8.3.x | |
| 8.4.x | 8.4.x | N/A** | 7.17.x - 8.4.x | 7.17.x - 8.4.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x - 8.4.x | 8.4.x |
| 8.5.x | 8.5.x | N/A** | 7.17.x - 8.5.x | 7.17.x - 8.5.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x - 8.5.x | 8.5.x |
| 8.6.x | 8.6.x | N/A** | 7.17.x - 8.6.x | 7.17.x - 8.6.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x - 8.6.x | 8.6.x |
| 8.7.x | 8.7.x | N/A** | 7.17.x - 8.7.x | 7.17.x - 8.7.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.8.x | N/A**** | 7.17.x - 8.7.x | 8.7.x |
| 8.8.x | 8.8.x | N/A** | 7.17.x - 8.8.x | 7.17.x - 8.8.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x-8.8.x | N/A**** | 7.17.x - 8.8.x | 8.8.x |
| 8.9.x | 8.9.x | N/A** | 7.17.x - 8.9.x | 7.17.x - 8.9.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x-8.9.x | N/A**** | 7.17.x - 8.9.x | 8.9.x |
| 8.10.x | 8.10.x | N/A** | 7.17.x - 8.10.x | 7.17.x - 8.10.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.10.x | N/A**** | 7.17.x - 8.10.x | 8.10.x |
| 8.11.x | 8.11.x | N/A** | 7.17.x - 8.11.x | 7.17.x - 8.11.x | 7.17.x - 8.11.x | 7.17.x - 8.12.x | 7.17.x - 8.11.x | N/A**** | 7.17.x - 8.11.x | 8.11.x |
| 8.12.x | 8.12.x | N/A** | 7.17.x - 8.12.x | 7.17.x - 8.12.x | 7.17.x - 8.12.x | 7.17.x - 8.12.x | 7.17.x - 8.12.x | N/A**** | 7.17.x - 8.12.x | 8.12.x |
| 8.13.x | 8.13.x | N/A** | 7.17.x - 8.13.x | 7.17.x - 8.13.x | 7.17.x - 8.13.x | 7.17.x - 8.13.x | 7.17.x - 8.13.x | N/A**** | 7.17.x - 8.13.x | 8.13.x |
| 8.14.x | 8.14.x | N/A** | 7.17.x - 8.14.x | 7.17.x - 8.14.x | 7.17.x - 8.14.x | 7.17.x - 8.14.x |
^ Elasticsearch 输出兼容性 — Connector Clients、Beats、Logstash 和 Elastic Agent 将数据索引到 Elasticsearch
* 我们建议运行最新版本的 Connector Clients、Beats、Logstash、Elastic Agent 和 ES-Hadoop;也可以使用早期版本,但功能会有所减少。
** 从 6.3 版开始,Elastic Stack 的默认分发版中将包含 X-Pack 功能。请查看 https://www.elastic.co/what-is/open-x-pack。
*** APM Server 6.7 和 6.8 版可与 Elasticsearch 7.0 版一起使用,但数据必须使用升级助手进行迁移才能在 Kibana 7.0 版中可见。
**** App Search 从 7.7.0 版开始将移至企业搜索中。
***** Elastic Agent 已在 7.14 版中正式发布。以前的版本均为实验性质,兼容性有限
与 Logstash 的兼容性
上次更新时间:2024-06-05
| Logstash | Beats** | APM Server | Monitoring & Management Elasticsearch Cluster* |
|---|---|---|---|
| 2.4.x | 1.0.x-5.6.x | N/A | N/A |
| 5.0.x | 1.3.x-5.6.x | N/A | N/A |
| 5.1.x | 5.0.x-5.6.x | N/A | N/A |
| 5.2.x | 5.0.x-5.6.x | N/A | 5.2.x - 5.6.x |
| 5.3.x | 5.0.x-5.6.x | N/A | 5.3.x - 5.6.x |
| 5.4.x | 5.0.x-5.6.x | N/A | 5.4.x - 5.6.x |
| 5.5.x | 5.0.x-5.6.x | N/A | 5.5.x - 5.6.x |
| 5.6.x | 5.6.x-6.8.x | N/A | 5.6.x - 6.0.x |
| 6.0.x | 5.6.x-6.8.x | N/A | 6.0.x - 6.8.x |
| 6.1.x | 5.6.x-6.8.x | N/A | 6.1.x - 6.8.x |
| 6.2.x | 5.6.x-6.8.x | N/A | 6.2.x - 6.8.x |
| 6.3.x | 5.6.x-6.8.x | N/A | 6.3.x - 6.8.x |
| 6.4.x | 5.6.x-6.8.x | N/A | 6.4.x - 6.8.x |
| 6.5.x | 5.6.x-6.8.x | N/A | 6.5.x - 6.8.x |
| 6.6.x | 5.6.x-6.8.x | N/A | 6.6.x - 6.8.x |
| 6.7.x | 5.6.x-6.8.x | 6.7.x - 6.8.x | 6.7.x - 6.8.x |
| 6.8.x | 5.6.x-6.8.x | 6.8.x | 6.8.x |
| 7.0.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x |
| 7.1.x | 6.8.x-7.17.x | 7.1.x-7.17.x | 7.1.x-7.17.x |
| 7.2.x | 6.8.x-7.17.x | 7.2.x-7.17.x | 7.2.x-7.17.x |
| 7.3.x | 6.8.x-7.17.x | 7.3.x-7.17.x | 7.3.x-7.17.x |
| 7.4.x | 6.8.x-7.17.x | 7.4.x-7.17.x | 7.4.x-7.17.x |
| 7.5.x | 6.8.x-7.17.x | 7.5.x-7.17.x | 7.5.x-7.17.x |
| 7.6.x | 6.8.x-7.17.x | 7.6.x-7.17.x | 7.6.x-7.17.x |
| 7.7.x | 6.8.x-7.17.x | 7.7.x-7.17.x | 7.7.x-7.17.x |
| 7.8.x | 6.8.x-7.17.x | 7.8.x-7.17.x | 7.8.x-7.17.x |
| 7.9.x | 6.8.x-7.17.x | 7.9.x-7.17.x | 7.9.x-7.17.x |
| 7.10.x | 6.8.x-7.17.x | 7.10.x-7.17.x | 7.10.x-7.17.x |
| 7.11.x | 6.8.x-7.17.x | 7.11.x-7.17.x | 7.11.x-7.17.x |
| 7.12.x | 6.8.x-7.17.x | 7.12.x-7.17.x | 7.12.x-7.17.x |
| 7.13.x | 6.8.x-7.17.x | 7.13.x-7.17.x | 7.13.x-7.17.x |
| 7.14.x | 6.8.x-7.17.x | 7.14.x-7.17.x | 7.14.x-7.17.x |
| 7.15.x | 6.8.x-7.17.x | 7.15.x-7.17.x | 7.15.x-7.17.x |
| 7.16.x | 6.8.x-7.17.x | 7.16.x-7.17.x*** | 7.16.x-7.17.x |
| 7.17.x | 6.8.x-7.17.x | 7.17.x*** | 7.17.x |
| 8.0.x | 7.17.x-8.14.x | 8.0.x-8.14.x*** | 8.0.x-8.14.x |
| 8.1.x | 7.17.x-8.14.x | 8.1.x-8.14.x*** | 8.1.x-8.14.x |
| 8.2.x | 7.17.x-8.14.x | 8.2.x-8.14.x*** | 8.2.x-8.14.x |
| 8.3.x | 7.17.x-8.14.x | 8.3.x-8.14.x*** | 8.3.x-8.14.x |
| 8.4.x | 7.17.x-8.14.x | 8.4.x-8.14.x*** | 8.4.x-8.14.x |
| 8.5.x | 7.17.x-8.14.x | 8.5.x-8.14.x*** | 8.5.x-8.14.x |
| 8.6.x | 7.17.x-8.14.x | 8.6.x-8.14.x*** | 8.6.x-8.14.x |
| 8.7.x | 7.17.x-8.14.x | 8.7.x-8.14.x*** | 8.7.x-8.14.x |
| 8.8.x | 7.17.x-8.14.x | 8.8.x-8.14.x*** | 8.8.x-8.14.x |
| 8.9.x | 7.17.x-8.14.x | 8.9.x-8.14.x*** | 8.9.x-8.14.x |
| 8.10.x | 7.17.x-8.14.x | 8.10.x-8.14.x*** | 8.10.x-8.14.x |
| 8.11.x | 7.17.x-8.14.x | 8.11.x-8.14.x*** | 8.11.x-8.14.x |
| 8.12.x | 7.17.x-8.14.x | 8.12.x-8.14.x*** | 8.12.x-8.14.x |
| 8.13.x | 7.17.x-8.14.x | 8.13.x-8.14.x*** | 8.13.x-8.14.x |
| 8.14.x | 7.17.x-8.14.x | 8.14.x*** | 8.14.x |
* 兼容性适用于监测和管理 Elasticsearch 集群以及任何通过其路由指标的 Elasticsearch 集群。这包括在 xpack.monitoring.elasticsearch.url 和 xpack.management.elasticsearch.url 设置中引用的任何集群。强烈建议在 Elasticsearch、Kibana 和 Logstash 中运行相同的次要版本,以体验最佳的监测和管理功能。对于 6.2 及更早的版本,必须在所有产品上安装 X-Pack。
** 在 7.4 版之前,Functionbeat 仅与作为输出目标的 Elasticsearch 兼容。不支持 Logstash 和其他输出。从 7.4 版开始,Functionbeat 支持 Elasticsearch 和 Logstash 输出。
*** 只有独立型 APM 服务器(不通过 Elastic Agent 管理)支持输出到 Logstash
与 Beats 的兼容性
上次更新时间:2024-06-05
| Beats** | Logstash | Monitoring Elasticsearch Cluster* | Uptime |
|---|---|---|---|
| 1.3.x | 2.0.x-5.0.x | N/A | N/A |
| 5.0.x | 2.0.x-5.6.x | N/A | N/A |
| 5.1.x | 2.0.x-5.6.x | N/A | N/A |
| 5.2.x | 2.0.x-5.6.x | N/A | N/A |
| 5.3.x | 2.0.x-5.6.x | N/A | N/A |
| 5.4.x | 2.0.x-5.6.x | N/A | N/A |
| 5.5.x | 2.0.x-5.6.x | N/A | N/A |
| 5.6.x | 5.6.x-6.8.x | N/A | N/A |
| 6.0.x | 5.6.x-6.8.x | N/A | N/A |
| 6.1.x | 5.6.x-6.8.x | N/A | N/A |
| 6.2.x | 5.6.x-6.8.x | 6.2.x | N/A |
| 6.3.x | 5.6.x-6.8.x | 6.3.x-6.8.x | N/A |
| 6.4.x | 5.6.x-6.8.x | 6.4.x-6.8.x | N/A |
| 6.5.x | 5.6.x-6.8.x | 6.5.x-6.8.x | N/A |
| 6.6.x | 5.6.x-6.8.x | 6.6.x-6.8.x | N/A |
| 6.7.x | 5.6.x-6.8.x | 6.7.x-6.8.x | 6.7.x-6.8.x |
| 6.8.x | 5.6.x-6.8.x | 6.8.x - 7.15.x | 6.7.x-6.8.x |
| 7.0.x | 6.8.x-7.17.x | 7.0.x-7.17.x | 7.0.x-7.17.x*** |
| 7.1.x | 6.8.x-7.17.x | 7.1.x-7.17.x | 7.0.x-7.17.x*** |
| 7.2.x | 6.8.x-7.17.x | 7.2.x-7.17.x | 7.0.x-7.17.x*** |
| 7.3.x | 6.8.x-7.17.x | 7.3.x-7.17.x | 7.0.x-7.17.x*** |
| 7.4.x | 6.8.x-7.17.x | 7.4.x-7.17.x | 7.0.x-7.17.x*** |
| 7.5.x | 6.8.x-7.17.x | 7.5.x-7.17.x | 7.0.x-7.17.x*** |
| 7.6.x | 6.8.x-7.17.x | 7.6.x-7.17.x | 7.0.x-7.17.x*** |
| 7.7.x | 6.8.x-7.17.x | 7.7.x-7.17.x | 7.0.x-7.17.x*** |
| 7.8.x | 6.8.x-7.17.x | 7.8.x-7.17.x | 7.0.x-7.17.x*** |
| 7.9.x | 6.8.x-7.17.x | 7.9.x-7.17.x | 7.0.x-7.17.x*** |
| 7.10.x | 6.8.x-7.17.x | 7.10.x-7.17.x | 7.0.x-7.17.x*** |
| 7.11.x | 6.8.x-7.17.x | 7.11.x-7.17.x | 7.0.x-7.17.x*** |
| 7.12.x | 6.8.x-7.17.x | 7.12.x-7.17.x | 7.0.x-7.17.x*** |
| 7.13.x | 6.8.x-7.17.x | 7.13.x-7.17.x | 7.0.x-7.17.x*** |
| 7.14.x | 6.8.x-7.17.x | 7.14.x-7.17.x | 7.0.x-7.17.x*** |
| 7.15.x | 6.8.x-7.17.x | 7.15.x-7.17.x | 7.0.x-7.17.x*** |
| 7.16.x | 6.8.x-7.17.x | 7.16.x-7.17.x | 7.0.x-7.17.x*** |
| 7.17.x | 7.17.x-8.14.x | 7.17.x | 7.0.x-7.17.x*** |
| 8.0.x | 7.17.x-8.14.x | 7.17.x-8.14.x | 7.17.x-8.3.x |
| 8.1.x | 7.17.x-8.14.x | 7.17.x-8.14.x | 7.17.x-8.3.x |
| 8.2.x | 7.17.x-8.14.x | 7.17.x-8.14.x | 7.17.x-8.3.x |
| 8.3.x | 7.17.x-8.14.x | 7.17.x-8.14.x | 7.17.x-8.3.x |
| 8.4.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.5.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.6.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.7.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.8.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.9.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.10.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.11.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.12.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.13.x | 7.17.x-8.14.x | 7.17.x-8.14.x | |
| 8.14.x | 7.17.x-8.14.x | 8.14.x |
* 兼容性适用于监测 Elasticsearch 集群以及任何通过其路由指标的 Elasticsearch 集群。这包括在 xpack.monitoring.elasticsearch 设置中引用的任何集群。强烈建议在 Elasticsearch、Kibana 和 Beats 中运行相同的次要版本,以体验最佳的监测功能。对于 6.2 版,必须在所有产品上安装 X-Pack。
** Functionbeat 仅与作为输出目标的 Elasticsearch 兼容。不支持 Logstash 和其他输出。
*** Uptime 7.x 与 Heartbeat 6.x 或更低版本不兼容。
** 强烈建议 Beats 使用与 Elasticsearch 相同或更低的版本。
** Beats 需要与 Elasticsearch 的版本相同或更低
集群架构
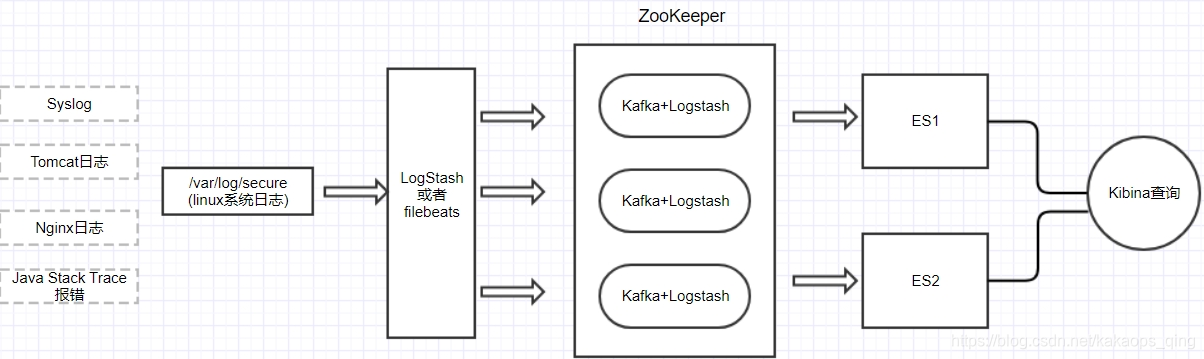
组件说明
| 组件 | 说明 |
|---|---|
| kibana | 是一个基于 Elasticsearch 的数据可视化和分析平台,可以对来自任何来源的任何数据进行全面透彻的分析,实现可观测性、安全和搜索。 |
| elasticsearch | ⼀个开源的⾼扩展的分布式全⽂搜索引擎,是整个Elastic Stack技术栈的核⼼。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。 |
| logsearch | 一款免费开源的服务器端数据处理管道,能够从多个来源采集数据,转换数据,并将规范的数据存储到您选择的目标位置 |
| kafka | ⼀个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应⽤程序。 kafka是⼀个基于分布式的发布订阅模型的消息队列(Message Queue,即MQ),主要应用于日志分析和⼤数据实时处理领域。 |
| ZooKeeper | 一种开源的分布式协调服务,由雅虎公司开发。它可以帮助分布式应用程序实现数据同步、配置管理、命名服务等功能,并具有高可用性、可靠性和可扩展性等特性。 |
| beats | Beats 是 Elastic Stack 的一部分,它是一系列轻量级的数据采集器。Beats 可以在你的服务器上采集各种类型的数据,并将这些数据发送到 Elasticsearch 或者 Logstash 进行后续处理。 |
一、主机规划
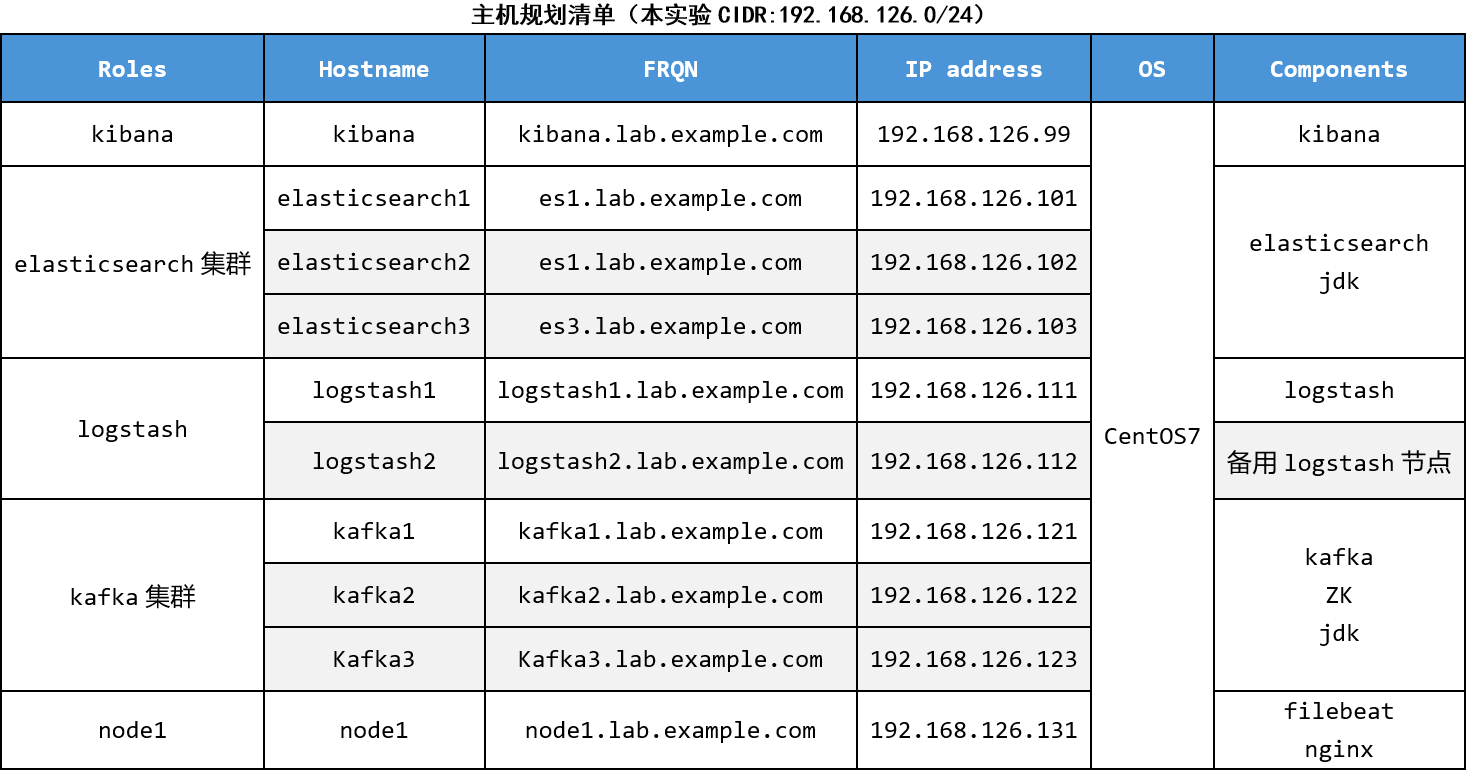
注意:Elasticsearch集群的高可用性配置最少需要3台节点。这是因为Elasticsearch使用一个叫做Zen Discovery的算法来进行节点之间的选举和通信,而这个算法要求多数派(quorum)来决定集群的状态和选举主节点。
二、封装ELFK模板机
1. 安装CentOS7虚拟机
安装略🤨
2. 配置yum源
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum makecache
3. 安装常用软件
yum install -y vim bash-completion wget
echo "source /usr/share/bash-completion/bash_completion" >>~/.bashrc
source ~/.bashrc
4. 把主机规划清单写入/etc/hosts
cat > /etc/hosts << EOF
127.0.0.1 localhost
192.168.126.99 kibana kibana.lab.example.com
192.168.126.101 elasticsearch1 es1.lab.example.com
192.168.126.102 elasticsearch2 es2.lab.example.com
192.168.126.103 elasticsearch3 es3.lab.example.com
192.168.126.111 logstash1 logstash1.lab.example.com
192.168.126.112 logstash2 logstash2.lab.example.com
192.168.126.121 kafka1 kafka1.lab.example.com
192.168.126.122 kafka2 kafka2.lab.example.com
192.168.126.123 kafka3 kafka3.lab.example.com
192.168.126.121 zookeeper1 zookeeper1.lab.example.com
192.168.126.122 zookeeper2 zookeeper2.lab.example.com
192.168.126.123 zookeeper3 zookeeper3..lab.example.com
192.168.126.131 node1 node1.lab.example.com
EOF
5. 关闭防火墙
systemctl disable --now firewalld && systemctl is-enabled firewalld
6. 时间同步
yum install -y ntpdate
crontab -e
* * * * * /usr/sbin/ntpdate -u ntp.aliyun.com && /sbin/hwclock -w
systemctl enable ntpdate --now && systemctl is-enabled ntpdate
7. 封装模板
history -c
init 0
-
关机后,删除光驱设备,创建快照,以备后续使用。
-
使用该模板虚拟机克隆出 kafka、elasticsearch1、logstash、kibana、node1五台 VM。
-
登录虚拟机按照主机规划清单分别设置主机名,修改网卡 地址。99、101、111、121、131改成自己的地址规划
kibana节点
hostnamectl set-hostname kibana
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.99"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
elasticsearch1节点
hostnamectl set-hostname elasticsearch1
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.101"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
elasticsearch2节点
hostnamectl set-hostname elasticsearch2
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.102"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
elasticsearch3节点
hostnamectl set-hostname elasticsearch3
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.103"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
logstash1节点
hostnamectl set-hostname logstash1
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.111"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
logstash2节点
hostnamectl set-hostname logstash2
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.112"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
kafka1节点
hostnamectl set-hostname kafka1
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.121"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
kafka2
hostnamectl set-hostname kafka2
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.122"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
kafka3
hostnamectl set-hostname kafka3
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.123"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
node1
hostnamectl set-hostname node1
sed -i 's/dhcp/static/g' /etc/sysconfig/network-scripts/ifcfg-ens33
sed -i '/^UUID/d' /etc/sysconfig/network-scripts/ifcfg-ens33
cat >> /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
IPADDR="192.168.126.131"
NETMASK="255.255.255.0"
GATEWAY="192.168.126.2"
DNS1="192.168.126.2"
EOF
systemctl restart network.service
以上虚拟机依次做快照
三、部署elasticsearch
1. 准备
[root@elasticsearch1 ~]# export ELASTICSEARCHS="elasticsearch1 elasticsearch2 elasticsearch3"
[root@elasticsearch1 ~]# ssh-keygen -N '' -f ~/.ssh/id_rsa
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do ssh-copy-id $x;done
# 动态定义 ELASTICSEARCHS 变量
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS; do
# 在远程主机上将变量添加到 ~/.bashrc 中
ssh $x "echo 'export ELASTICSEARCHS=\"elasticsearch1 elasticsearch2 elasticsearch3\"' >> ~/.bashrc"
# 可选:在远程主机上刷新 ~/.bashrc 文件
ssh $x "source ~/.bashrc"
done
2. 安装jdk环境
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do ssh $x curl -o jdk-8u391-linux-x64.tar.gz https://download.oracle.com/otn/java/jdk/8u391-b13/b291ca3e0c8548b5a51d5a5f50063037/jdk-8u391-linux-x64.tar.gz?AuthParam=1720344062_087fda2b5c300fbc61a3efc0b214baa1;done
[root@elasticsearch1 ~]# vim ~/jdk.sh
#!/bin/bash
# 查找 JDK 压缩包所在目录,并将设置为变量 JAVA
JAVA=$(find / -name '*jdk*tar*' -exec dirname {} \; | head -n 1)
# 查找 JDK 压缩包的名字,设置为变量 JDK
JDK=$(find / -name '*jdk*tar*' 2>/dev/null | awk -F/ '{print $NF}' | head -n 1)
# 打印 JDK 压缩包目录和文件
echo "JAVA Directory: $JAVA"
echo "JDK File: $JDK"
# 切换到压缩包所在目录
cd "$JAVA"
# 验证文件格式是否为 gzip
filetype=$(file "$JDK" | grep -o 'gzip compressed data')
if [ "$filetype" != "gzip compressed data" ]; then
echo "File is not in gzip format."
exit 1
fi
# 解压到 /usr/local/ 目录下
tar xf "$JDK" -C /usr/local/
if [ $? -ne 0 ]; then
echo "Failed to extract $JDK."
exit 1
fi
# 找到解压后的目录名,并设置为变量 JDKAPP
JDKAPP=$(find /usr/local/ -maxdepth 1 -type d | grep jdk | awk -F/ '{print $NF}' | head -n 1)
echo "JDKAPP Directory: $JDKAPP"
# 检查解压后的目录是否存在
if [ -z "$JDKAPP" ]; then
echo "Extracted JDK directory not found."
exit 1
fi
# 做软链接,便于 shell 环境识别命令
ln -sfn /usr/local/"$JDKAPP" /usr/local/jdk
# 创建环境变量文件
cat > /etc/profile.d/jdk.sh << 'EOF1'
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib/:$JRE_HOME/lib/
EOF1
echo "请执行 source /etc/profile.d/jdk.sh 命令,刷新文件"
[root@elasticsearch1 ~]# chmod 700 jdk.sh
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do scp -p jdk.sh $x:~/;done
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do ssh $x 'bash jdk.sh && source /etc/profile.d/jdk.sh';done
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do ssh $x java -version;done
注意在循环中使用
ssh执行命令并使其生效时,source命令可能无法按预期工作,因为它只对当前 shell 生效。可以将source命令放在远程 shell 会话
3. 安装elasticsearch
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do ssh $x yum install -y https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-x86_64.rpm; done
1) 修改配置文件
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS;do ssh $x cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak;done
[root@elasticsearch1 ~]# for x in $ELASTICSEARCHS; do
ssh $x "cat > /etc/elasticsearch/elasticsearch.yml << 'EOF'
cluster.name: zzp-elk
node.name: $x
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: [\"elasticsearch1\",\"elasticsearch2\",\"elasticsearch3\"]
cluster.initial_master_nodes: [\"elasticsearch1\",\"elasticsearch2\",\"elasticsearch3\"]
EOF"
done
2) 启动服务
所有节点删除之前的临时数据(先停止服务!)
for x in $ELASTICSEARCHS;do ssh -t $x sudo systemctl stop elasticsearch; ssh -t $x sudo systemctl status elasticsearch; ssh -t $x sudo rm -rf /var/{lib,log}/elasticsearch/* /tmp/*; ssh -t $x sudo ls -l /var/{lib,log}/elasticsearch /tmp/;done
批量启动服务
for x in $ELASTICSEARCHS; do ssh -t $x sudo systemctl enable elasticsearch ; ssh -t $x sudo systemctl restart elasticsearch; ssh -t $x sudo systemctl status elasticsearch ; done
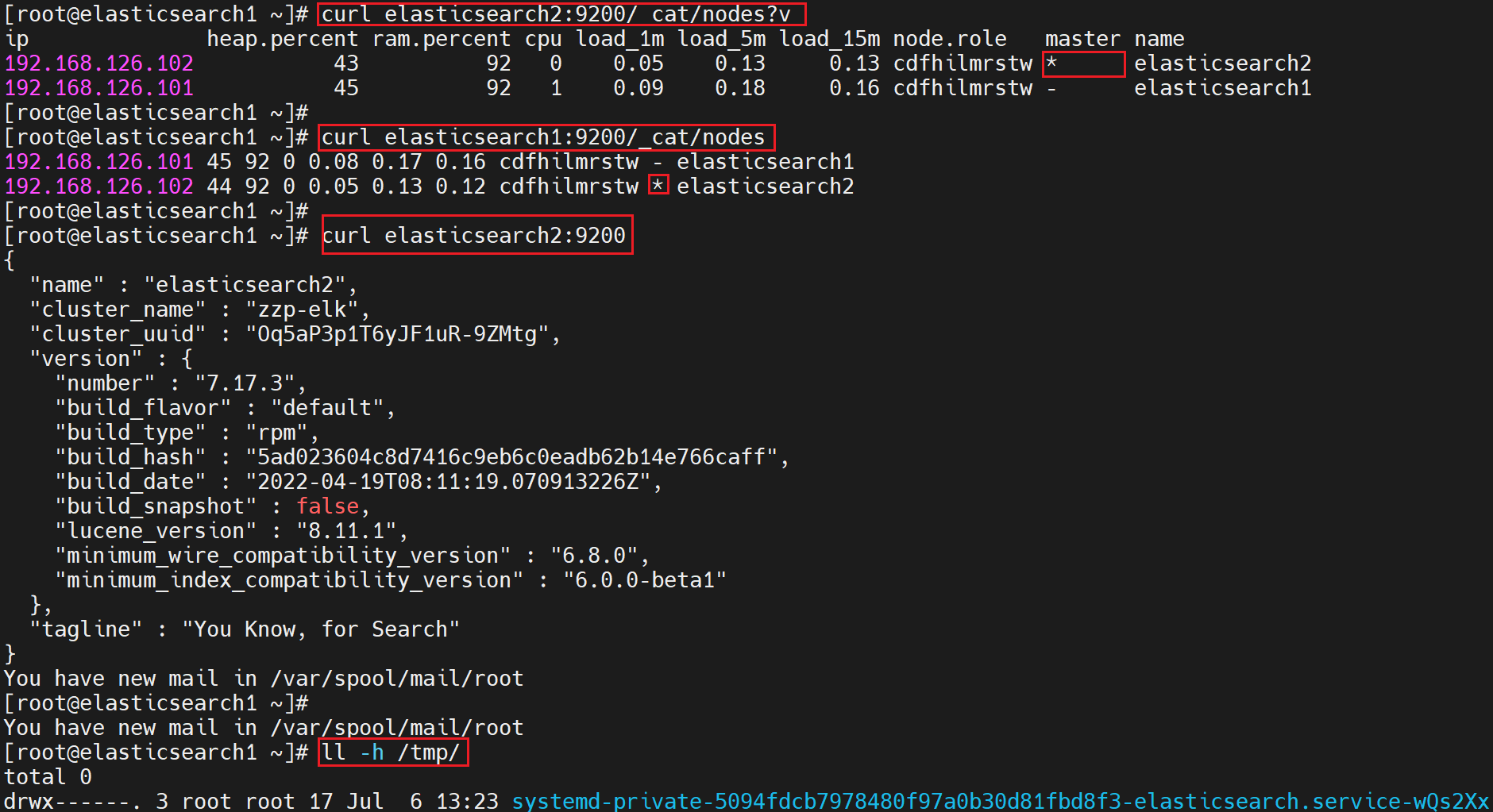
3) 查看集群的健康状态
[root@elasticsearch1 ~]# curl -X GET "http://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.126.103 51 93 23 0.93 0.31 0.15 cdfhilmrstw - elasticsearch3
192.168.126.102 35 90 11 0.40 0.17 0.10 cdfhilmrstw * elasticsearch2
192.168.126.101 25 93 7 0.23 0.16 0.09 cdfhilmrstw - elasticsearch1
[root@elasticsearch1 ~]# curl -X GET "http://localhost:9200/_cluster/health?pretty"
{
"cluster_name" : "zzp-elk",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 3,
"active_shards" : 6,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
四、部署logstash
1. 准备
配置每个节点到每个节点的无密码访问
[root@logstash1 ~]# export NODES="logstash1 logstash2"
[root@logstash1 ~]# ssh-keygen -N '' -f ~/.ssh/id_rsa
[root@logstash1 ~]# for node in $NODES;do ssh-copy-id $node;done
[root@logstash1 ~]# for logstash in logstash1 logstash2; do
# 在远程主机上将变量添加到 ~/.bashrc 中
ssh $logstash "echo 'export LOGSTASHS=\"logstash1 logstash2\"' >> ~/.bashrc"
# 可选:在远程主机上刷新 ~/.bashrc 文件
ssh $logstash "source ~/.bashrc"
done
2. 安装logstash
[root@logstash1 ~]# for logstash in $LOGSTASHS;do ssh $logstash yum install -y https://artifacts.elastic.co/downloads/logstash/logstash-7.17.3-x86_64.rpm; done
3. 启动服务并设置开机启动
[root@logstash1 ~]# for x in $LOGSTASHS; do ssh -t $x sudo systemctl enable logstash --now; ssh -t $x sudo systemctl status logstash ; done
4. 服务调优
待完善
[root@logstash1 ~]# vim /etc/logstash/jvm.options
-Xms256m
-Xmx256m
[root@logstash1 ~]# vim /etc/logstash/logstash.yml
pipeline.workers: 2 # 设置为2个工作线程,根据需要调整 # 默认与cpu核心相同
# 使用 systemd 的 CPU 限制功能
[Service]
CPUQuota=50%
5. 软链接便于shell环境识别
[root@logstash1 ~]# for x in $LOGSTASHS; do ssh -t $x ln -s /usr/share/logstash/bin/logstash /usr/local/bin/; done
6. 测试服务(可以先测一个节点)
[root@logstash1 ~]# for x in $LOGSTASHS; do ssh -t $x install -d ~/config-logstash; done
cat >~/config-logstash/01-file-to-es.yaml<< EOF
input{
file {
# 指定收集的路径
path => ["/var/log/cron"]
# 指定⽂件的读取位置,仅在".sincedb*"⽂件中没有记录的情况下⽣效!
start_position => "beginning" # 默认是 end
}
}
output {
elasticsearch {
hosts => ["192.168.126.101","192.168.126.102","192.168.126.103"]
data_stream => "true"
}
}
EOF
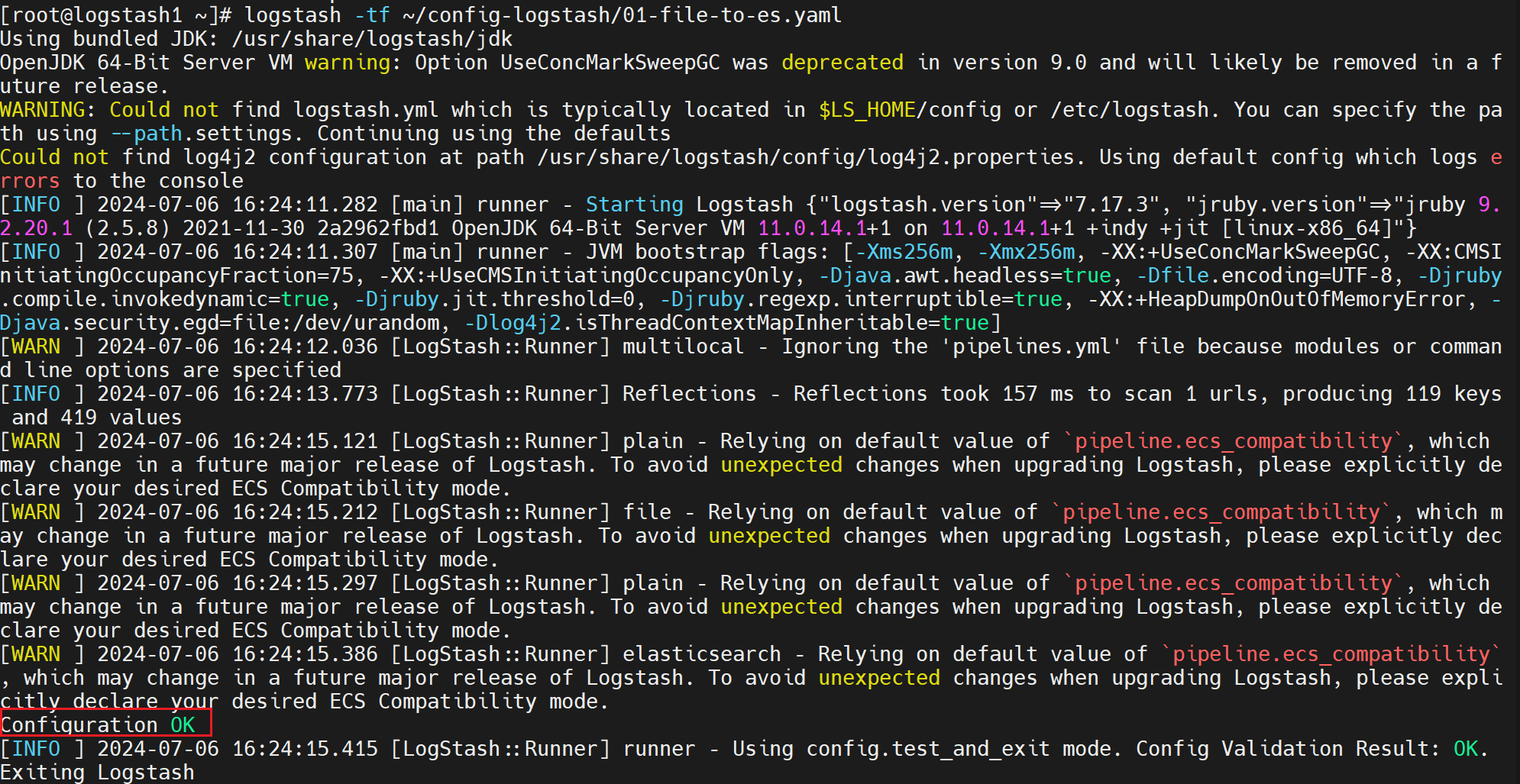
# 检查语法
[root@logstash1 ~]# logstash -tf ~/config-logstash/01-file-to-es.yaml
# 启动收集
[root@logstash1 ~]# logstash -f ~/config-logstash/01-file-to-es.yaml
收到返回消息在elasticsearch集群上查看
[root@logstash1 ~]# for x in elasticsearch1 elasticsearch2; do
echo "$x:" && curl -X GET "$x:9200/_cat/indices?v" && echo
done

五、部署kibana
1. 安装kibana
[root@kibana ~]# yum install -y https://artifacts.elastic.co/downloads/kibana/kibana-7.17.3-x86_64.rpm
2. 修改配置文件
[root@kibana ~]# cp /etc/kibana/kibana.yml /etc/kibana/kibana.yml.bak
[root@kibana ~]# cat > /etc/kibana/kibana.yml <<EOF
server.port: 5601
server.host: "0.0.0.0" # 该配置指示Kibana服务器绑定到所有可用的网络接口
server.name: "zzp-kibana"
# #配置了Kibana连接的Elasticsearch集群地址和端口
elasticsearch.hosts: ["http://192.168.126.101:9200","http://192.168.126.102:9200","http://192.168.126.103:9200"]
i18n.locale: "zh-CN"
EOF
3. 启动服务
[root@kibana ~]# systemctl enable kibana.service --now
4. 游览器访问kibana UI界面
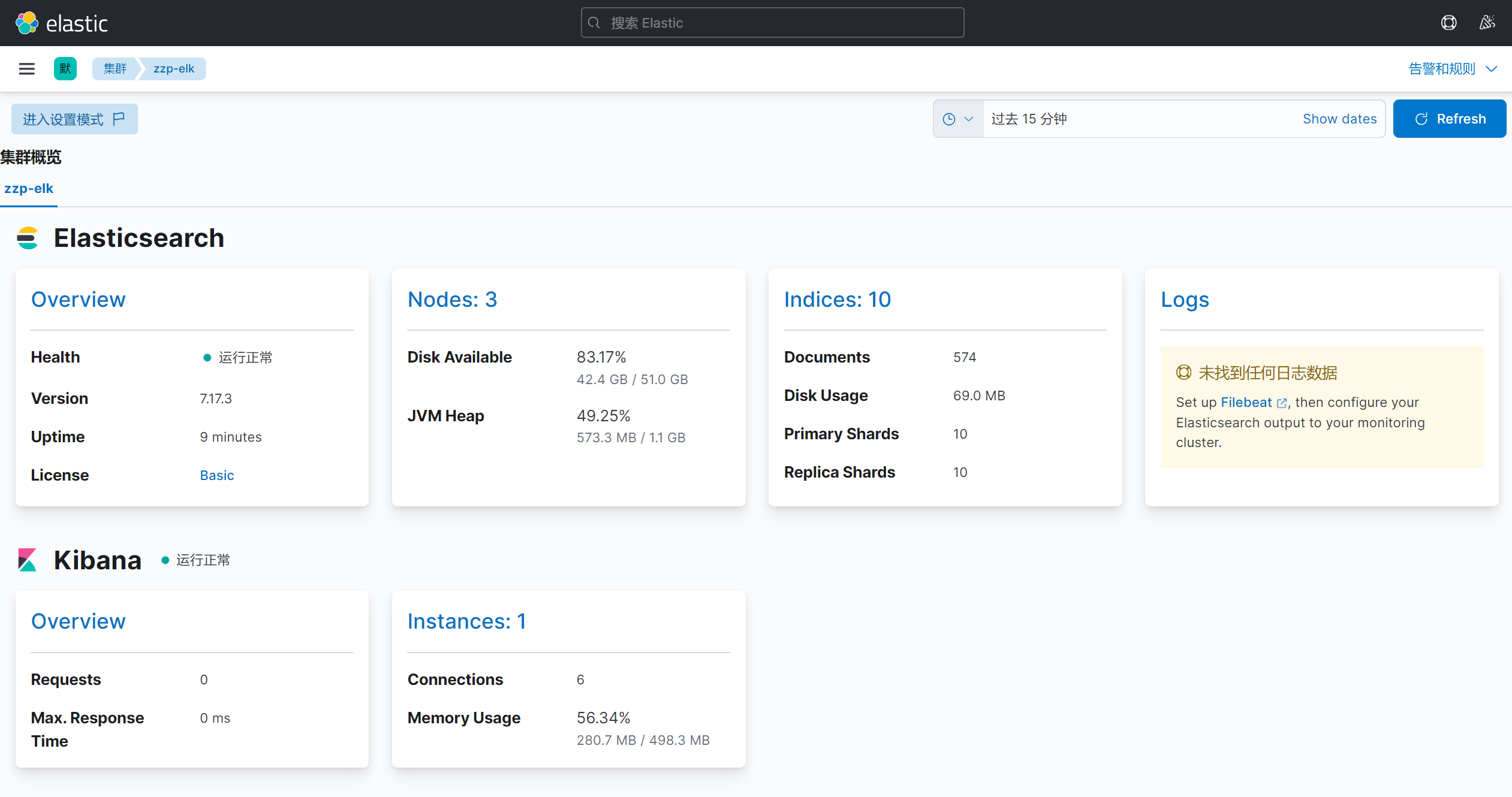
六、部署beats
1. 安装测试环境
[root@node1 ~]# cat >/etc/yum.repos.d/nginx.repo <<EOF
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/\$releasever/\$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/\$releasever/\$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOF
[root@node1 ~]# yum install -y nginx
[root@node1 ~]# systemctl enable nginx.service --now
2. 安装filebeat
[root@node1 ~]# yum install -y https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.3-x86_64.rpm
3. 修改配置文件
1) 备份
[root@node1 ~]# cp -a /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml.bak
2) 编写配置文件
[root@node1 ~]# cat > /etc/filebeat/filebeat.yml <<EOF
# Filebeat 配置文件
# 配置文件输入部分
filebeat.inputs:
# Nginx 日志输入
- type: filestream # 使用 filestream 输入类型来处理日志文件
id: nginx # 输入的唯一标识符
paths:
# 指定要收集的 Nginx 日志文件路径
- /var/log/nginx/access.log # Nginx 访问日志
- /var/log/nginx/error.log # Nginx 错误日志
fields:
log_type: nginx # 添加一个字段,用于标识日志来源
fields_under_root: true # 将自定义字段添加到事件的根级别
encoding: utf-8 # 日志文件的编码格式
ignore_older: 72h # 忽略超过 72 小时未更新的文件
scan_frequency: 10s # 每 10 秒扫描一次日志文件
# Cron 日志输入
- type: filestream # 使用 filestream 输入类型来处理日志文件
id: cron-time # 输入的唯一标识符
paths:
# 指定要收集的 Cron 日志文件路径
- "/var/log/cron*" # 以 /var/log/cron 开头的所有日志文件
fields:
time: true # 添加一个字段,用于标识日志来源
fields_under_root: true # 将自定义字段添加到事件的根级别
encoding: utf-8 # 日志文件的编码格式
ignore_older: 72h # 忽略超过 72 小时未更新的文件
# Nginx 日志输入(使用旧的 log 类型作为参考)
# 如果您之前使用的是 log 类型的输入,可以保留以下内容用于参考
# - type: log
# id: nginx
# paths:
# - /var/log/nginx/access.log
# - /var/log/nginx/error.log
# fields:
# log_type: nginx
# fields_under_root: true
# encoding: utf-8
# ignore_older: 72h
# scan_frequency: 10s
# 输出到 Elasticsearch
output.elasticsearch:
# 指定 Elasticsearch 实例的地址列表
hosts:
- "http://192.168.126.101:9200" # Elasticsearch 主节点地址
- "http://192.168.126.102:9200" # Elasticsearch 从节点地址
- "http://192.168.126.103:9200" # Elasticsearch 备用节点地址
index: "zzp-linux-nginx-%{+yyyy.MM.dd}"
# 禁⽤索引⽣命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "zzp-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "test-linux*"
# Kibana 配置(用于 Filebeat 的索引模板和仪表板)
setup.kibana:
# 指定 Kibana 实例的地址
host: "http://192.168.126.101:5601" # Kibana 地址,用于可视化数据
# 输出到 Logstash(如果需要将数据发送到 Logstash)
# output.logstash:
# hosts: ["localhost:5044"] # Logstash 实例的地址
# 配置 Filebeat 运行状态监控
# filebeat.monitoring.enabled: true
# filebeat.monitoring.elasticsearch:
# hosts: ["http://localhost:9200"]
# username: "monitoring_user"
# password: "monitoring_password"
# filebeat.monitoring.kibana:
# hosts: ["http://localhost:5601"]
# username: "monitoring_user"
# password: "monitoring_password"
EOF
3) 启动服务
[root@node1 ~]# systemctl start filebeat.service
4) 模拟测试数据
[root@node1 ~]# cat random_request.sh
#!/bin/bash
# 随机生成桌面端用户代理字符串
random_desktop_user_agent() {
local os_platforms=("Windows NT 10.0" "Macintosh; Intel Mac OS X 10_15_7" "X11; Linux x86_64")
local browser_info="AppleWebKit/537.36 (KHTML, like Gecko) Chrome/$((RANDOM % 50 + 50)).0.0.0 Safari/537.36 Edg/$((RANDOM % 900 + 100)).$((RANDOM % 100)).$((RANDOM % 100)).$((RANDOM % 100))"
echo "Mozilla/5.0 (${os_platforms[$RANDOM % ${#os_platforms[@]}]}) $browser_info"
}
# 随机生成移动设备用户代理字符串
random_mobile_user_agent() {
local mobile_platforms=("Android" "iPhone" "iPad" "Windows Phone")
local platform=${mobile_platforms[$RANDOM % ${#mobile_platforms[@]}]}
local brand
local model
case "$platform" in
"Android")
brand=$(echo "Samsung Huawei Xiaomi OPPO Vivo" | tr ' ' '\n' | shuf -n 1)
model=$(echo "Galaxy S21 P40 Pro Mi 11 Find X3 Pro X50 Pro" | tr ' ' '\n' | shuf -n 1)
;;
"iPhone")
brand="Apple"
model="iPhone $((RANDOM % 6 + 8))"
;;
"iPad")
brand="Apple"
model="iPad $((RANDOM % 4 + 6))"
;;
"Windows Phone")
brand="Microsoft"
model="Windows Phone $((RANDOM % 3 + 8))"
;;
esac
local os_version="$((RANDOM % 6 + 10)).0"
local browser_info="AppleWebKit/605.1.15 (KHTML, like Gecko) Chrome/$((RANDOM % 50 + 50)).0.0.0 Mobile Safari/537.36 Edg/$((RANDOM % 900 + 100)).$((RANDOM % 100)).$((RANDOM % 100)).$((RANDOM % 100))"
echo "Mozilla/5.0 ($brand $model; CPU OS $os_version like Mac OS X) $browser_info"
}
# 随机生成用户代理字符串
random_user_agent() {
if ((RANDOM % 2 == 0)); then
random_desktop_user_agent
else
random_mobile_user_agent
fi
}
# 生成随机 IP 地址
random_ip() {
echo "$((RANDOM % 256)).$((RANDOM % 256)).$((RANDOM % 256)).$((RANDOM % 256))"
}
# 读取用户输入
read -p "请输入请求的URL(不带协议,如example.com),默认值为本机地址(localhost): " url
url=${url:-localhost}
read -p "请输入端口号(如80),默认值为80: " port
port=${port:-80}
read -p "请输入访问时间间隔(秒),默认值为5秒: " interval
interval=${interval:-5}
# 构建完整的请求URL
full_url="http://$url:$port"
# 输出用户输入的信息
echo "请求的URL: $full_url"
echo "访问时间间隔: $interval 秒"
# 循环发送请求
while true; do
# 构建请求头
user_agent=$(random_user_agent)
x_forwarded_for=$(random_ip)
# 发送GET请求
response=$(curl -s -H "User-Agent: $user_agent" -H "X-Forwarded-For: $x_forwarded_for" "$full_url")
# 打印请求结果
echo "请求URL: $full_url"
echo "请求头: User-Agent: $user_agent"
echo "请求头: X-Forwarded-For: $x_forwarded_for"
echo "响应内容: $response"
# 休眠指定的时间间隔
sleep "$interval"
done
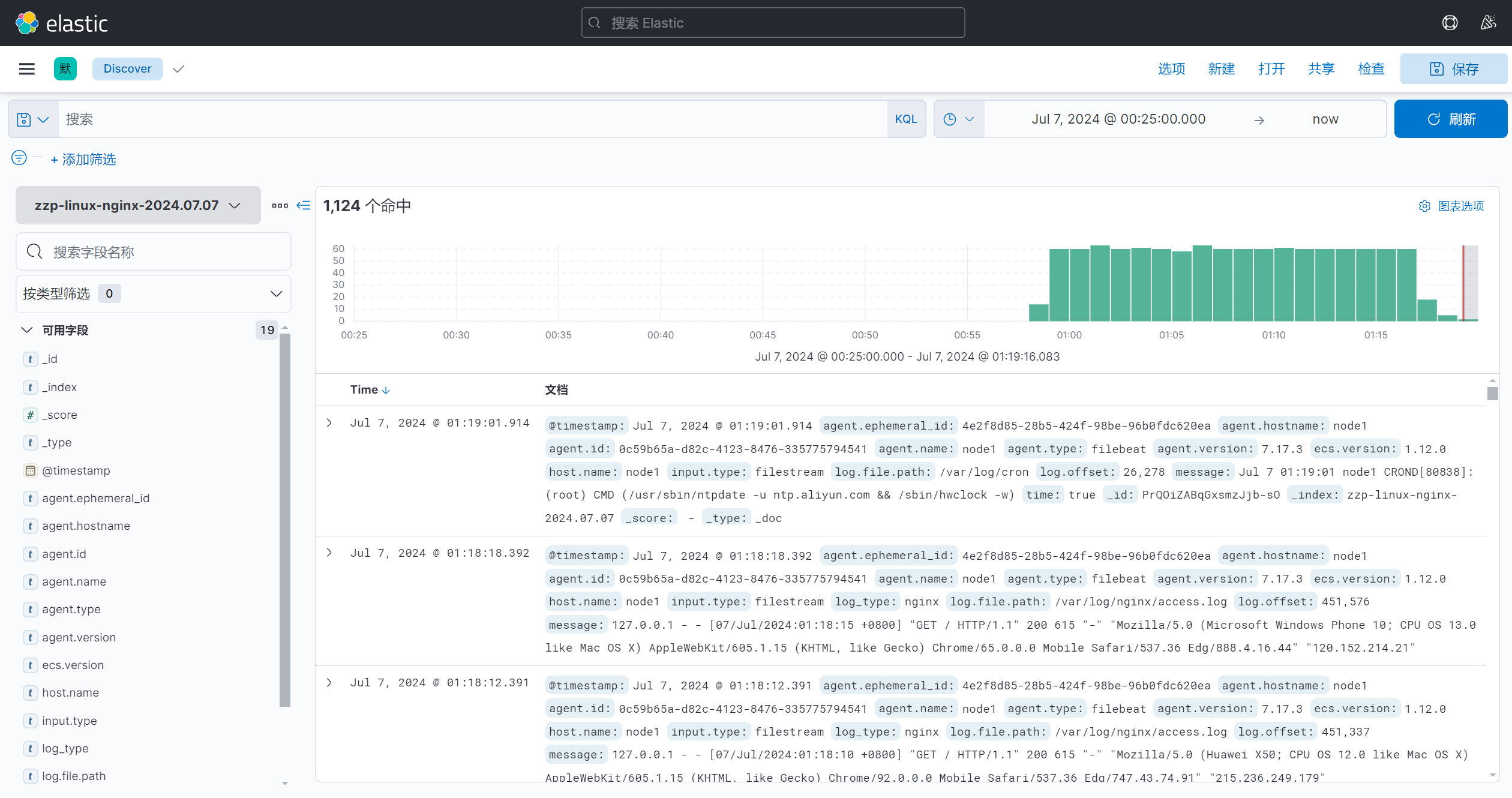
七、部署zookeeper

1. 准备
1) 免密钥和定义变量
[root@kafka1 ~]# export ZOOKEEPERS="zookeeper1 zookeeper2 zookeeper3"
[root@kafka1 ~]# ssh-keygen -N '' -f ~/.ssh/id_rsa
[root@kafka1 ~]# for x in $ZOOKEEPERS;do ssh-copy-id $x;done
# 动态定义 KAFKAS 变量
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
# 在远程主机上将变量添加到 ~/.bashrc 中
ssh $x "echo 'export ZOOKEEPERS=\"zookeeper1 zookeeper2 zookeeper3\"' >> ~/.bashrc"
# 可选:在远程主机上刷新 ~/.bashrc 文件
ssh $x "source ~/.bashrc"
done
2) 部署java环境
[root@kafka1 ~]# for x in $ZOOKEEPERS;do ssh $x curl -o jdk-8u391-linux-x64.tar.gz https://download.oracle.com/otn/java/jdk/8u391-b13/b291ca3e0c8548b5a51d5a5f50063037/jdk-8u391-linux-x64.tar.gz?AuthParam=1720346810_7b6e0232ee0caf4f70cd6be87be02fc3;done
[root@kafka1 ~]# vim ~/jdk.sh
#!/bin/bash
# 查找 JDK 压缩包所在目录,并将设置为变量 JAVA
JAVA=$(find / -name '*jdk*tar*' -exec dirname {} \; | head -n 1)
# 查找 JDK 压缩包的名字,设置为变量 JDK
JDK=$(find / -name '*jdk*tar*' 2>/dev/null | awk -F/ '{print $NF}' | head -n 1)
# 打印 JDK 压缩包目录和文件
echo "JAVA Directory: $JAVA"
echo "JDK File: $JDK"
# 切换到压缩包所在目录
cd "$JAVA"
# 验证文件格式是否为 gzip
filetype=$(file "$JDK" | grep -o 'gzip compressed data')
if [ "$filetype" != "gzip compressed data" ]; then
echo "File is not in gzip format."
exit 1
fi
# 解压到 /usr/local/ 目录下
tar xf "$JDK" -C /usr/local/
if [ $? -ne 0 ]; then
echo "解压失败 $JDK."
exit 1
fi
echo "解压成功"
# 找到解压后的目录名,并设置为变量 JDKAPP
JDKAPP=$(find /usr/local/ -maxdepth 1 -type d | grep jdk | awk -F/ '{print $NF}' | head -n 1)
echo "JDKAPP Directory: $JDKAPP"
# 检查解压后的目录是否存在
if [ -z "$JDKAPP" ]; then
echo "Extracted JDK directory not found."
exit 1
fi
# 做软链接,便于 shell 环境识别命令
ln -sfn /usr/local/"$JDKAPP" /usr/local/jdk
# 创建环境变量文件
cat > /etc/profile.d/jdk.sh << 'EOF1'
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib/:$JRE_HOME/lib/
EOF1
echo "请执行 source /etc/profile.d/jdk.sh 命令,刷新文件"
[root@kafka1 ~]# chmod 700 jdk.sh
[root@kafka1 ~]# for x in $ZOOKEEPERS;do scp -p jdk.sh $x:~/;done
[root@kafka1 ~]# for x in $ZOOKEEPERS;do ssh $x 'bash jdk.sh && source /etc/profile.d/jdk.sh';done
[root@kafka1 ~]# for x in $ZOOKEEPERS;do ssh $x java -version;done
注意在循环中使用 ssh 执行命令并使其生效时,source 命令可能无法按预期工作,因为它只对当前 shell 生效。可以将 source 命令放在远程 shell 会话
2. 安装zookeeper
1)下载安装包
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x curl -Lo /usr/local/apache-zookeeper-3.8.4.tar.gz https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz -C -
done
2) 解压
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x tar -xf /usr/local/apache-zookeeper-3.8.4.tar.gz -C /usr/local/
done
3) 创建软连接
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x ln -sv /usr/local/apache-zookeeper-3.8.4-bin /usr/local/zookeeper
done
3 修改配置文件
1) 创建数据目录和日志目录
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x install -d /usr/local/zookeeper/{data,logs}
done
2) 备份配置文件
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x cp /usr/local/zookeeper/conf/{zoo_sample.cfg,zoo.cfg}
done
zookeeper 运行时会寻找名为 zoo.cfg 的配置文件,所以需要将 zoo_sample.cfg 改名为 zoo.cfg
3) 创建myid
[root@kafka1 ~]# for host in $ZOOKEEPERS; do
for host in $ZOOKEEPERS; do
# 通过 ping 命令获取 IP 地址
ip=$(ping -c 1 $host | grep 'PING' | awk -F'[()]' '{print $2}')
# 如果 IP 为空,则给出默认值
if [ -z "$ip" ]; then
third_octet="0"
else
# 提取 IP 的第四部分
third_octet=$(echo $ip | awk -F. '{print $4}')
fi
echo "主机: $host, IP: $ip, 第四部分: $third_octet"
# 使用 SSH 将第三部分写入远程主机上的文件
ssh $host "echo $third_octet > /usr/local/zookeeper/data/myid"
done
4) 编写配置文件
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x "cat > /usr/local/zookeeper/conf/zoo.cfg <<EOF
#用于计算的时间单元,单位为毫秒。比如session超时:N* tickTime。
tickTime=2000
#用于集群,允许从节点连接并同步到master节点的初始化连接时间,以tickTime的倍数来表示。
initLimit=10
#用于集群,master主节点与从节点之间发送消息,请求和应答时间长度,超过一定的时间从节点就会被抛弃。(心跳机制)
syncLimit=5
#必须配置,比如用来存储事务文件的数据等。
dataDir=/usr/local/zookeeper/data
#日志目录,如果不配置会和dataDir公用
dataLogDir=/usr/local/zookeeper/logs
#连接服务器的端口,默认2181
clientPort=2181
#单个client与单台server之间的连接数的限制,是ip级别的,默认是60。假设设置为0。那么表明不作不论什么限制。请注意这个限制的使用范围,不过单台client机器与单台ZKserver之间的连接数限制,不是针对指定clientIP,也不是ZK集群的连接数限制,也不是单台ZK对全部client的连接数限制。
maxClientCnxns=1200
#这个參数和上面的參数搭配使用,这个參数指定了须要保留的文件数目
autopurge.snapRetainCount=10
# 3.4.0及之后版本号,ZK提供了自己主动清理事务日志和快照文件的功能,这个參数指定了清理频率。单位是小时。须要配置一个1或更大的整数,默认是0。表不开启自己主动清理功能
autopurge.purgeInterval=24
# server.myid=你的三个节点的ip地址:2888:3888
# 2888:集群内机器通讯使用
# 3888:选举leader使用的端口
server.$(ssh zookeeper1 cat /usr/local/zookeeper/data/myid)=zookeeper1:2888:3888
server.$(ssh zookeeper2 cat /usr/local/zookeeper/data/myid)=zookeeper2:2888:3888
server.$(ssh zookeeper3 cat /usr/local/zookeeper/data/myid)=zookeeper3:2888:3888
EOF"
done
5) 创建环境变量
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x 'cat > /etc/profile.d/zookeeper.sh <<EOF
export ZK_HOME=/usr/local/zookeeper
export PATH=\$PATH:\$ZK_HOME/bin
echo 'Zookeeper PATH added: \$PATH'
EOF'
done
检查是否添加成功
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x source /etc/profile.d/zookeeper.sh
done
注意:需要重新打开终端
4. 启动zk服务
1) 批量启动脚本
[root@kafka1 ~]# vim zookeeper_start.sh
#!/bin/bash
ZOOKEEPERS="zookeeper1 zookeeper2 zookeeper3"
# 提示用户输入命令
read -p "请输入命令 (start|stop|restart|status): " cmd
# 判断用户输入的命令是否有效
if [[ "$cmd" != "start" && "$cmd" != "stop" && "$cmd" != "restart" && "$cmd" != "status" ]]; then
echo "无效参数,必须输入 {start|stop|restart|status}"
exit
fi
# 定义函数功能
function zookeeperManager() {
case $cmd in
start)
echo "启动服务"
remoteExecution start
;;
stop)
echo "停止服务"
remoteExecution stop
;;
restart)
echo "重启服务"
remoteExecution restart
;;
status)
echo "查看状态"
remoteExecution status
;;
*)
echo "无效参数,必须输入 {start|stop|restart|status}"
;;
esac
}
# 定义执行的命令
function remoteExecution() {
for i in $ZOOKEEPERS; do
tput setaf 2
echo ========== ${i} zkServer.sh $1 ================
tput setaf 9
ssh ${i} "source /etc/profile.d/zookeeper.sh; zkServer.sh $1 2>/dev/null"
done
}
# 调用函数
zookeeperManager
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
scp ~/zookeeper_start.sh $x:/usr/local/bin/
done
[root@kafka1 ~]# for x in $ZOOKEEPERS; do
ssh $x chmod 700 /usr/local/bin/zookeeper_start.sh
done
2) 在任意节点执行
[root@kafka1 ~]# zookeeper_start.sh
5. 相关命令
- 启动zk
[root@kafka1 ~]# zkServer.sh start
- 停止zk
[root@kafka1 ~]# zkServer.sh stop
- 查看zk的角色状态
[root@kafka1 ~]# zkServer.sh status
- 查看zk的版本信息
[root@kafka1 ~]# zkServer.sh version
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Apache ZooKeeper, version 3.8.4 2024-02-12 22:16 UTC
- 查看zk是否启动
[root@kafka1 ~]# ps -ef | grep zookeeper
- 连接客户端
[root@kafka1 ~]# zkCli.sh
- 客户端常用命令
# 查看根节点下的子节点
[zk: localhost:2181(CONNECTED) 2] ls /
[zookeeper, zzp-kafka-3_2_0]
zookeeper节点通常是由ZooKeeper服务器自动创建的,用于存储ZooKeeper内部的元数据,如集群的配置信息、会话信息等。
zzp-kafka-3_2_0节点是为Kafka集群配置的一部分。Kafka经常使用ZooKeeper来存储集群的元数据,如broker的注册信息、主题的分区和副本信息等。
[zk: localhost:2181(CONNECTED) 3] ls /zzp-kafka-3_2_0
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification]
admin:可能用于存储与Kafka管理操作相关的数据。brokers:存储Kafka集群中所有broker的信息。cluster:可能包含集群级别的配置或状态信息。config:用于存储Kafka主题的配置信息。consumers:存储消费者组的信息,如偏移量(offsets)。controller:与Kafka集群的控制器(controller)相关的信息,控制器负责在集群中分配分区和副本的领导者。controller_epoch:控制器的纪元(epoch),用于确保控制器的操作是线性的。feature:可能用于跟踪Kafka支持的特性或功能。isr_change_notification:用于在ISR(In-Sync Replicas,同步副本集)发生变化时通知消费者或生产者。latest_producer_id_block:与生产者ID分配相关的元数据。log_dir_event_notification:可能用于在日志目录发生更改时提供通知。
八、部署kafka
1. 准备
[root@kafka1 ~]# export KAFKAS="kafka1 kafka2 kafka3"
[root@kafka1 ~]# ssh-keygen -N '' -f ~/.ssh/id_rsa
[root@kafka1 ~]# for x in $KAFKAS;do ssh-copy-id $x;done
# 动态定义 ELASTICSEARCHS 变量
[root@elasticsearch1 ~]# for x in $KAFKAS; do
# 在远程主机上将变量添加到 ~/.bashrc 中
ssh $x "echo 'export KAFKAS=\"kafka1 kafka2 kafka3\"' >> ~/.bashrc"
# 可选:在远程主机上刷新 ~/.bashrc 文件
ssh $x "source ~/.bashrc"
done
2. 安装jdk环境
由于zookeeper和kafka在同一节点上,已经部署过来,这里就不再部署。
3. 安装kafka
1) 下载安装包
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x curl -Lo /usr/local/kafka_2.13-3.6.2.tgz https://downloads.apache.org/kafka/3.6.2/kafka_2.13-3.6.2.tgz -C -
done
2) 解压
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x tar -xf /usr/local/kafka_2.13-3.6.2.tgz -C /usr/local/
done
3) 创建软连接
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x ln -sv /usr/local/kafka_2.13-3.6.2 /usr/local/kafka
done
4. 修改配置文件
1) 创建日志目录
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x install -d /usr/local/kafka/logs
done
2) 备份配置文件
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x cp /usr/local/kafka/config/{server.properties,server.properties.bak}
done
3) 编写配置文件
[root@kafka1 ~]# for x in $KAFKAS; do ssh $x "cat > /usr/local/kafka/config/server.properties <<EOF
broker.id=$(ping -c 1 $x | awk -F '[().]' '/PING/ {print $5}')
#listeners=PLAINTEXT://:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/zzp-kafka-3_2_0
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
EOF"
done
broker.id:节点在集群中的唯一ID,需要与dataDir/myid文件中的内容保持一致,取值范围为1~255。
/zzp-kafka-3_2_0:这部分是Zookeeper中的路径,用于存储Kafka集群的配置信息。
[root@kafka1 ~]# for x in $KAFKAS; do ssh $x "cat > /usr/local/kafka/config/server.properties <<EOF
broker.id=$(ping -c 1 $x | awk -F '[().]' '/PING/ {print $5}')\
log.dirs=/usr/local/kafka/logs
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/zzp-kafka-3_2_0
EOF"
done
4) 创建环境变量
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x 'cat > /etc/profile.d/kafka.sh <<EOF
export KAFKA_HOME=/usr/local/kafka
export PATH=\$PATH:\$KAFKA_HOME/bin
echo 'kafka PATH added: \$PATH'
EOF'
done
检查是否添加成功
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x source /etc/profile.d/kafka.sh
done
重新打开终端
5. 启动服务
1) 启动脚本
[root@kafka1 ~]# vim kafka_start.sh
#!/bin/bash
# Kafka 配置文件路径
KAFKA_CONFIG="/usr/local/kafka/config/server.properties"
# Kafka 日志文件路径
KAFKA_LOGS="/usr/local/kafka/logs"
# Kafka 安装目录
KAFKA_HOME="/usr/local/kafka"
# Kafka 启动命令
KAFKA_START_CMD="$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_CONFIG"
# Kafka 进程检查函数
check_kafka_process() {
if ps aux | grep 'kafka.Kafka' | grep -v grep > /dev/null; then
return 0
else
return 1
fi
}
# Kafka 启动函数
start_kafka() {
echo -e "\033[1;34m正在启动 Kafka 实例...\033[0m"
# 检查 Kafka 是否已经在运行
if check_kafka_process; then
echo -e "\033[1;33mKafka 实例已经在运行。\033[0m"
return
fi
# 启动 Kafka 实例
$KAFKA_START_CMD > $KAFKA_LOGS/server.log 2>&1 &
# 等待 Kafka 启动
sleep 10
# 检查 Kafka 是否启动成功
if check_kafka_process; then
echo -e "\033[1;32mKafka 启动成功。\033[0m"
else
echo -e "\033[1;31mKafka 启动失败。请检查以下内容:\033[0m"
# 打印 Kafka 的日志文件内容,若 tail 失败则显示从最近一次 ERROR 开始的错误日志
echo -e "\033[1;34mKafka 日志文件内容:\033[0m"
if [ ! -f $KAFKA_LOGS/server.log ]; then
echo -e "\033[1;31m错误: 日志文件 $KAFKA_LOGS/server.log 不存在。\033[0m"
return
fi
if grep -i "ERROR" $KAFKA_LOGS/server.log > /dev/null; then
echo -e "\033[1;31m从最近一次 'ERROR' 开始的日志内容如下:\033[0m"
# 获取最近一次 ERROR 的行号
ERROR_LINE=$(grep -ni "ERROR" $KAFKA_LOGS/server.log | tail -n 1 | cut -d: -f1)
if [ -n "$ERROR_LINE" ]; then
# 从最近一次 ERROR 的位置开始显示 50 行日志
tail -n +$ERROR_LINE $KAFKA_LOGS/server.log | head -n 50
else
echo -e "\033[1;31m未找到 'ERROR' 关键字。\033[0m"
fi
else
echo -e "\033[1;31m日志文件中没有找到 'ERROR' 关键字。\033[0m"
tail -n 50 $KAFKA_LOGS/server.log || echo -e "\033[1;31m无法读取 Kafka 日志文件。请手动检查日志文件。\033[0m"
fi
echo -e "\033[1;33m可能的启动失败原因:\033[0m"
echo "1. 检查 Kafka 配置文件是否正确。"
echo "2. 检查 ZooKeeper 是否运行正常并能连接到 Kafka。"
echo "3. 检查 Kafka 日志文件中是否有其他错误信息。"
echo "4. 检查端口是否被其他进程占用。"
echo "5. 确保 Kafka 的 log.dirs 目录具有正确的读写权限。"
fi
}
# Kafka 停止函数
stop_kafka() {
echo -e "\033[1;31m正在停止 Kafka 实例...\033[0m"
kafka_pid=$(ps aux | grep 'kafka.Kafka' | grep -v grep | awk '{print $2}')
if [ -z "$kafka_pid" ]; then
echo -e "\033[1;33mKafka 实例没有运行。\033[0m"
return
fi
kill -TERM $kafka_pid
if [ $? -eq 0 ]; then
echo -e "\033[1;31mKafka 实例已停止。\033[0m"
else
echo -e "\033[1;31m停止 Kafka 实例时出错。\033[0m"
fi
}
# Kafka 重启函数
restart_kafka() {
stop_kafka
start_kafka
}
# Kafka 状态检查函数
status_kafka() {
if check_kafka_process; then
echo -e "\033[1;32mKafka 实例正在运行。\033[0m"
else
echo -e "\033[1;33mKafka 实例未在运行。\033[0m"
fi
}
# 交互式菜单函数
interactive_menu() {
while true; do
# 显示带有不同颜色的提示信息
echo -ne "\033[1;34m请输入命令 (\033[1;32mstart\033[0m|\033[1;31mstop\033[0m|\033[1;33mrestart\033[0m|\033[1;36mstatus\033[0m|\033[1;35mexit\033[0m): \033[0m"
read action
case "$action" in
start)
start_kafka
;;
stop)
stop_kafka
;;
restart)
restart_kafka
;;
status)
status_kafka
;;
exit)
echo -e "\033[1;32m退出脚本。\033[0m"
break
;;
*)
echo -e "\033[1;31m无效命令,请输入 \033[1;32mstart\033[0m、\033[1;31mstop\033[0m、\033[1;33mrestart\033[0m、\033[1;36mstatus\033[0m 或 \033[1;35mexit\033[0m。\033[0m"
;;
esac
done
}
# 执行交互式菜单
interactive_menu
2) 分发到每个节点
[root@kafka1 ~]# for x in $KAFKAS; do
scp ~/kafka_start.sh $x:/usr/local/bin/
done
[root@kafka1 ~]# for x in $KAFKAS; do
ssh $x chmod 700 /usr/local/bin/kafka_start.sh
done
6. 验证集群是否正常
- 创建topic
kafka-topics.sh --create --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --replication-factor 2 --partitions 3 --topic topic1
- 查看已经创建的所有Topic信息
kafka-topics.sh --list --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092

- 查看
topic1的详细信息
kafka-topics.sh --describe --topic topic1 --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092

- 消费者等待接收消息
# 可以启动多个消费者,消费者消费的都一样
kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --topic topic1 --from-beginning
# 多个消费者配置为同一个消费者组时,它们会共同消费 topic1 中的消息,每条消息只会被一个消费者处理一次。
kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --topic topic1 --from-beginning --group group1
- 重新打开一个终端,生产者准备发送消息
#!/bin/bash
# 初始化消息计数器
counter=1
# 启动生产者并显示回显
while true; do
message="message $(date '+%Y-%m-%d %H:%M:%S') - $counter"
echo "$message" | tee /dev/tty | kafka-console-producer.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --topic topic1
((counter++)) # 计数器自增
sleep 1 # 发送间隔
done
消费者1

消费者2

- 查看消费者消费情况
kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --describe --group group1

- 删除topic
kafka-topics.sh --delete --topic topic1 --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092