简介
HorizontalPodAutoscaler依据metrics-server周期性的收集特定资源的指标,按照用户指定的资源指标的平均阈值,自动扩缩工作负载资源副本数量,以满足业务需求。支持的工作负载:RelicationController、ReplicaSet、Deployment、Statefulset
- 如果业务负载指标持续超过设定的阈值,部署更多的Pods以应对增加的业务负载,但最多不少于minReplicas配置的最大副本数量。
- 如果业务负载指标持续低于设定的阈值,部署更多的Pods以应对增加的业务负载,但最多不少于minReplicas配置的最大副本数量
附注:VerticalPodAutoscaler意味着将更多的资源(例如:Memory或CPU)分配给已经为工作负载运行到的Pods。
安装 metrics-server
HAP 前提条件:
默认情况下,Horizontal Pod Autoscaler 控制器会从一系列的 API 中检索度量值。集群管理员需要确保下述条件,以保证 HPA 控制器能够访问这些 API:
- 对于资源指标,将使用 metrics.k8s.io API,一般由 metrics-server 提供。它可以作为集群插件启动。
- 对于自定义指标,将使用 custom.metrics.k8s.io API。它由其他度量指标方案厂商的“适配器(Adapter)” API 服务器提供。检查你的指标管道以查看是否有可用的 Kubernetes 指标适配器。
- 对于外部指标,将使用 external.metrics.k8s.io API。可能由上面的自定义指标适配器提供。
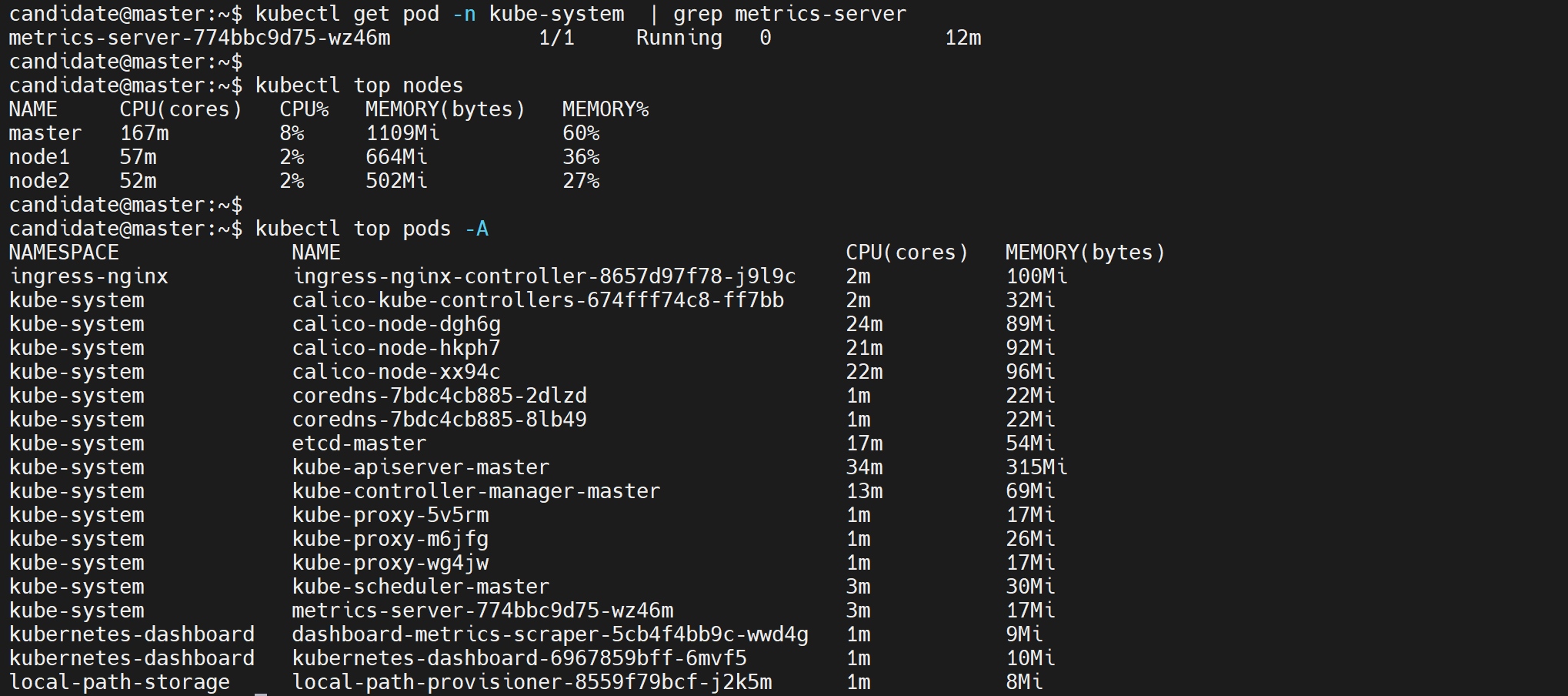
Kubernetes Metrics Server:
- Kubernetes Metrics Server 是 Cluster 的核心监控数据的聚合器,kubeadm 默认是不部署的。
- Metrics Server 供 Dashboard 等其他组件使用,是一个扩展的 APIServer,依赖于 API Aggregator。所以,在安装 Metrics Server 之前需要先在 kube-apiserver 中开启 API Aggregator。
- Metrics API 只可以查询当前的度量数据,并不保存历史数据。
- Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 下维护。
- 必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 kubelet Summary API 获取数据。
# 添加这行
# --enable-aggregator-routing=true
### 修改每个 API Server 的 kube-apiserver.yaml 配置开启 Aggregator Routing:修改 manifests 配置后 API Server 会自动重启生效。
cat /etc/kubernetes/manifests/kube-apiserver.yaml
Metrics-server安装地址:Releases · kubernetes-sigs/metrics-server (github.com)
# metrics-server 所使用的 docker 镜像默认存放在 k8s.gcr.io
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 或
curl -LO https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.3/components.yaml
修改components.yaml
...
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --kubelet-insecure-tls # 加上该启动参数,不加可能会报错
image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.1 # 镜像地址根据情况修改
imagePullPolicy: IfNotPresent
...
metrics-server pod无法启动,出现日志unable to fully collect metrics: ... x509: cannot validate certificate for because ... it doesn't contain any IP SANs ...
安装Metrics-server
kubectl apply -f components.yaml
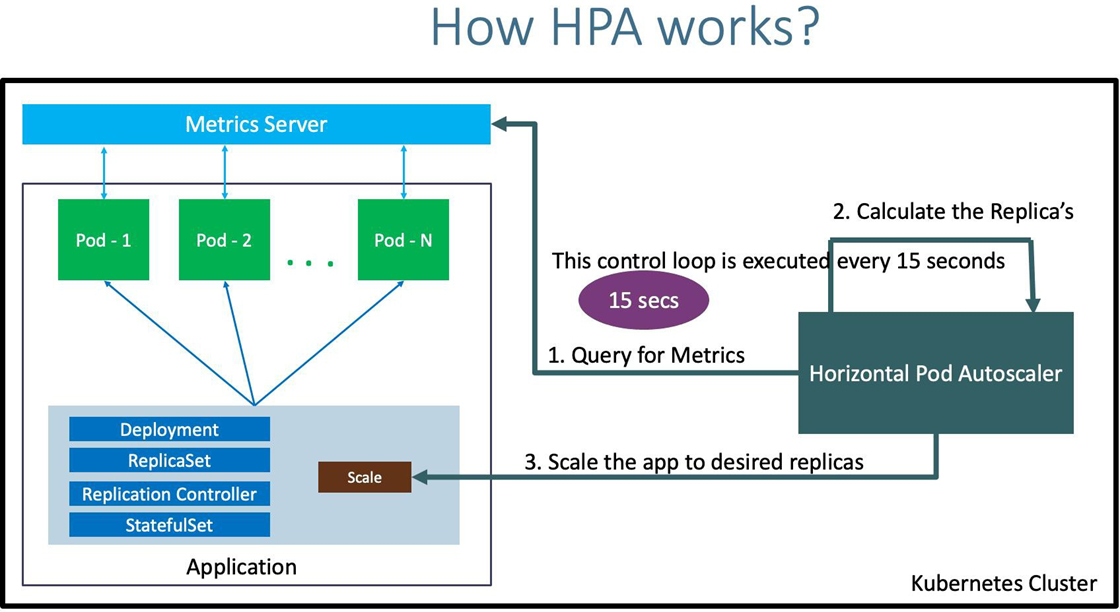
Horizontal Pod Autoscaler 工作原理
- 自动检测周期由
kube-controller-manager的--horizontal-pod-autoscaler-sync-period参数设置(默认间隔为 15 秒)。 - metrics-server 提供 metrics.k8s.io API 为pod资源的使用提供支持。
- 15s/周期 -> 查询metrics.k8s.io API -> 算法计算 -> 调用scale 调度 -> 特定的扩缩容策略执行。
算法
| 算法 | 说明 |
|---|---|
| desiredReplicas | 计算后,将发送到控制器的副本数量 |
| ceil() | 向上取整函数。例如ceil(12.18)是13 |
| currentReplicas | 控制器管理的缩放目标Pods对象的当前数量 |
| currentMetricValue | 当前指标的平均值。可以是800m或1.5Gi,自定义指标可以是每秒500个事件等。 |
| desiredMetricValue | 触发伸缩的指标平均阈值 |
desiredReplicas = ceil[ currentReplicas * ( currentMetricValue / desiredMetricValue ) ]
HPA伸缩范例:
假如我们有一个HPA配置,desiredMetricValue目标CPU使用率为60%。最小Pods数为5,最大Pods数14。currentReplicas当前8个Pods,currentMetricValue当前平均值CPU使用率为70%
currentMetricValue / desiredMetricValue = (70% / 60%) = 1.167 -1 > horizontal-pod-autoscaler-tolerance(0.1),触发扩充
desiredReplicas = ceil[ 8 * ( 70% / 60%) ] = 10
HPA全局参数
kube-controller-manager HPA全局参数说明:kube-controller-manager | Kubernetes
--horizontal-pod-autoscaler-initial-readiness-delay duration:HPA初始化延时等待时长,在此时间内的Pods被认为为就绪。默认为:30s
--horizontal-pod-autoscaler-sync-period:调用metric-server获取指定资源利用率指标的间隔时间,默认为:15s
--horizontal-pod-autoscaler-tolerance:当前指标/期望指标,如果扩缩比例接近1.0,即0.9-1.1,将会放弃本次扩缩操作。默认为 0.1
--horizontal-pod-autoscaler-downscale-stabilization:指标持续低于阈值的时长才触发缩容。消除短时间内的快速波动影响,平滑缩容。默认为:5m0s
--horizontal-pod-autoscaler-cpu-initialization-period:用于设置Pods的初始化时间,在此事件内的Pod,CPU资源度量值将不会被采纳。默认为:5m0s
相关字段


实验
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: hpa
name: hpa-demo
spec:
replicas: 1
selector:
matchLabels:
app: hpa
template:
metadata:
labels:
app: hpa
spec:
containers:
- image: nginx:stable-alpine
name: nginx
resources:
limits:
cpu: 500m
memory: 256Mi
requests: # 针对保障资源进行自动扩缩
cpu: 100m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
labels:
app: hpa
name: hpa-demo
spec:
ports:
- name: hpa
port: 8081
protocol: TCP
targetPort: 80
selector:
app: hpa
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-demo
minReplicas: 1
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization # CPU 利用率
averageUtilization: 60 # 当Deployment中Pod的平均CPU利用率超过60%时,HPA会考虑扩容;当平均CPU利用率低于60%时,可能
会缩容。
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 稳定窗口(秒),即使满足条件也要等待稳定窗口结束
policies:
- type: Percent # 按照百分比,减少pod数量=当前pod×10%
value: 10
periodSeconds: 60 # 60秒内最多
- type: Pods
value: 3
periodSeconds: 60
selectPolicy: Max
scaleUp:
stabilizationWindowSeconds: 5
policies:
- type: Percent
value: 20
periodSeconds: 15
- type: Pods
value: 3
periodSeconds: 15
selectPolicy: Max
压测
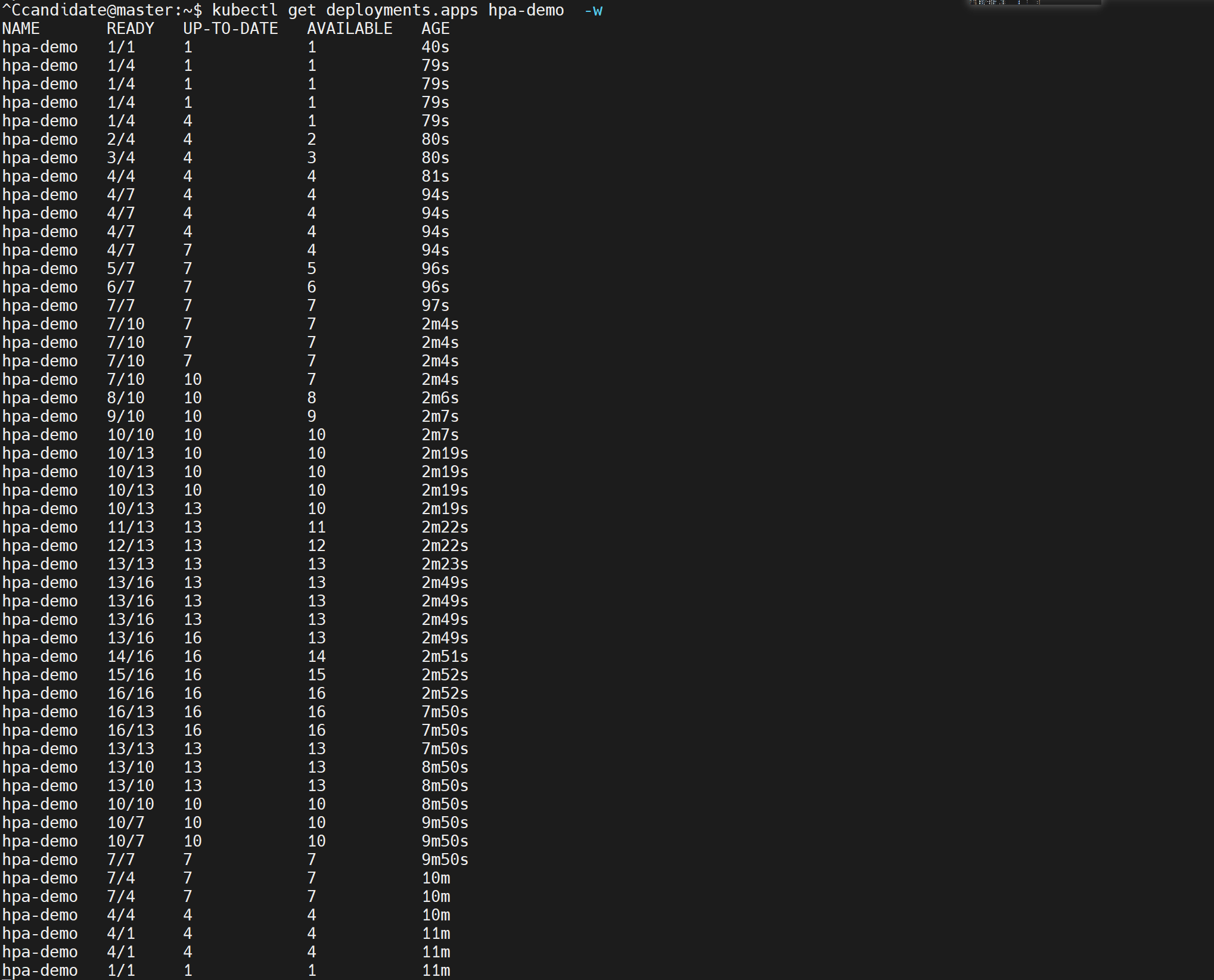
wrk -t1 -c4 -d120s http://10.96.79.175:8081/
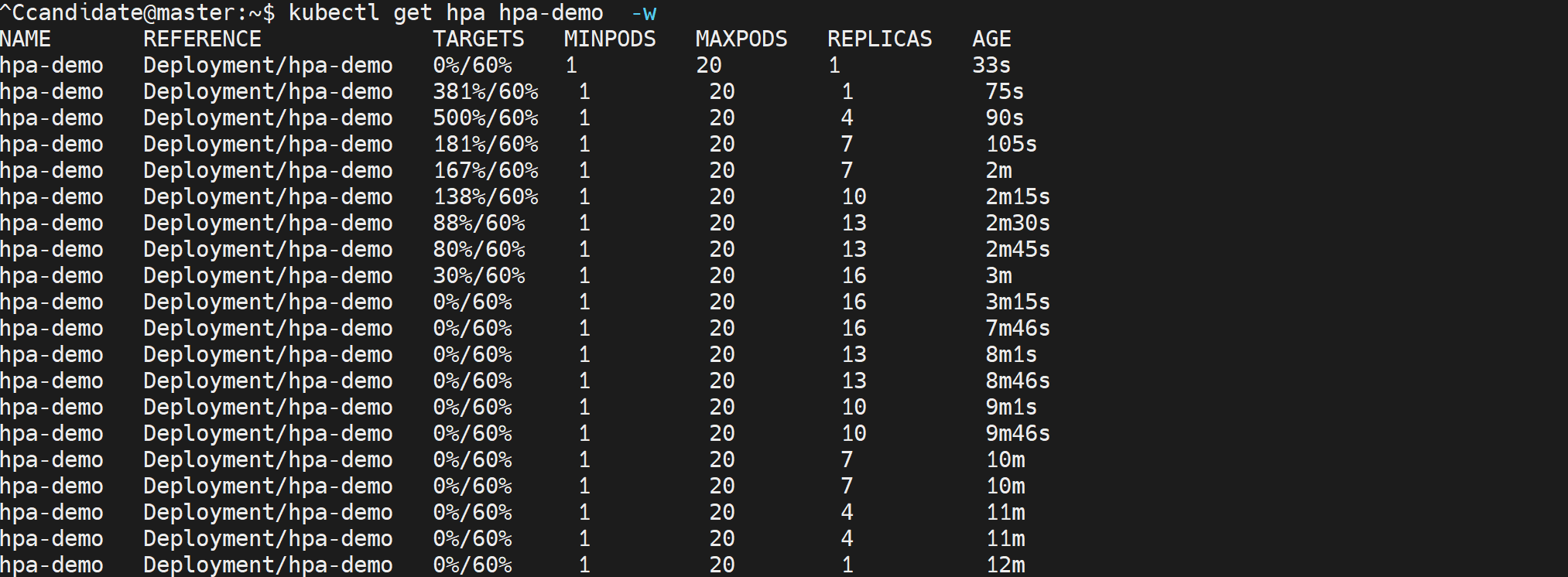
autoscaler默认每隔15秒,收集一次资源利用率